127. bibtex 插入参考文献
omit...
omit...
注意:解压压缩包到本地磁盘(解压目录不要有中文、空格)
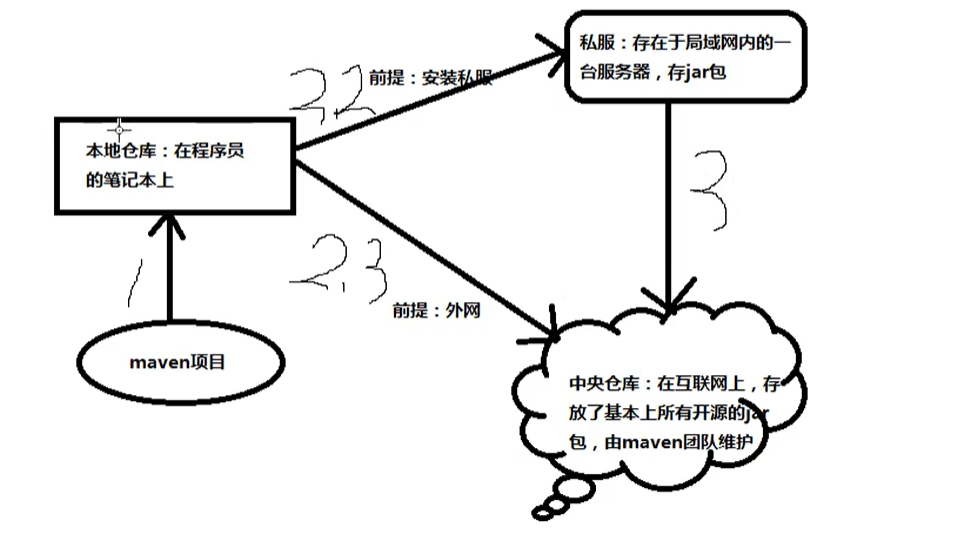
maven项目找jar包的过程

依赖管理:对jar包管理过程
项目构建:项目在编码完成后,对项目进行编译、测试、打包、部署等一系列操作都通过 命令 实现
通过maven命令将web项目发布到tomcat:
1
mvn tomcat:run
maven程序安装前提:maven程序java开发,它的运行依赖:jdk。
jdk需要有:
JAVE_HOME
MAVEN_HOME: bin目录上一级MAVEN_HOME 环境变量配置到 path 环境变量中: %MAVEN_HOME%\bin1 | mvn -v |
在本地磁盘上存储各种各样的jar包
bos_repository.zip)1 | <localRepository>[改为自己的本地仓库目录]</localRepository> |
对项目文件进行细分:
src: 项目源码pom.xml: project object module(maven项目核心配置文件)target: src项目源码编译完成存到target文件夹中(不属于maven项目标准目录结构)clean: 清理将项目根目录target目录清理
compile: 编译将项目中
.java文件编译为.class文件
test: 单元测试将项目根目录下
src/test/java目录下的单元测试类都会执行
单元测试类名有要求:XxxxTest.java
package: 打包将项目打包,导报项目根目录下target目录
install: 安装解决本地多个项目公用一个jar包
打包到本地仓库
在maven中存在“三套”生命周期,每一套生命周期相互独立,互不影响。
在一套生命周期内,执行后面的命令前面的命令会自动执行。
| 依赖范围 | 对于编译classpath有效 | 对于测试classpath有效 | 对于运行classpath有效 | 例子 |
|---|---|---|---|---|
| compile | Y | Y | Y | spring-core |
| test | - | Y | - | Junit |
| provided | Y | Y | - | servlet-api |
| runtime | - | Y | Y | JDBC驱动 |
| system | Y | Y | - | 本地的,maven仓库之外的类库 |
添加依赖范围:默认compile
privided: 运行部署到tomcat不再需要
如果将
servlet-api.jar设置为compile,打包后包含servlet-api.jar,war包部署到tomcat跟tomcat中存在的servlet-api.jar冲突,导致运行失败。
总结:如果使用到tomcat自带的jar包,一定要将项目依赖范围设置为:provided
Java 标准库自带的 java.util 包提供了集合类:Collection,它是除 Map 外所有其他集合类的根接口。Java 的 java.util 包主要提供了以下三种类型的集合:
Java 集合的设计有几个特点:一是实现了接口和实现类相分离,例如,有序表的接口是 List,具体的实现类有 ArrayList,LinkedList 等,二是支持泛型,我们可以限制在一个集合中只能放入同一种数据类型的元素,例如:
1
List<String> list = new ArrayList<>(); // 只能放入 String 类型
最后,Java 访问集合总是通过统一的方式——迭代器(Iterator)来实现,它最明显的好处在于无需知道集合内部元素是按什么方式存储的。
由于 Java 的集合设计非常久远,中间经历过大规模改进,我们要注意到有一小部分集合类是遗留类,不应该继续使用:
还有一小部分接口是遗留接口,也不应该继续使用:
List 是最基础的一种集合:它是一种有序列表。
List 的行为和数组几乎完全相同:List 内部按照放入元素的先后顺序存放,每个元素都可以通过索引确定自己的位置,List 的索引和数组一样,从 0 开始。
数组和 List 类似,也是有序结构,如果我们使用数组,在添加和删除元素的时候,会非常不方便。
在实际应用中,需要增删元素的有序列表,我们使用最多的是 ArrayList。实际上,ArrayList 在内部使用了数组来存储所有元素。例如,一个 ArrayList 拥有 5 个元素,实际数组大小为 6(即有一个空位)
当添加一个元素并指定索引到 ArrayList 时,ArrayList 自动移动需要移动的元素;
然后,往内部指定索引的数组位置添加一个元素,然后把 size 加 1;
继续添加元素,但是数组已满,没有空闲位置的时候,ArrayList 先创建一个更大的新数组,然后把旧数组的所有元素复制到新数组,紧接着用新数组取代旧数组;
现在,新数组就有了空位,可以继续添加一个元素到数组末尾,同时 size 加 1;
可见,ArrayList 把添加和删除的操作封装起来,让我们操作 List 类似于操作数组,却不用关心内部元素如何移动。
boolean add(E e)boolean add(int index, E e)int remove(int index)int remove(Object e)E get(int index)int size() 但是,实现 List 接口并非只能通过数组(即 ArrayList 的实现方式)来实现,另一种 LinkedList 通过 “链表” 也实现了 List 接口。在 LinkedList 中,它的内部每个元素都指向下一个元素:
1
2
3 ┌───┬───┐ ┌───┬───┐ ┌───┬───┐ ┌───┬───┐
HEAD ──>│ A │ ●─┼──>│ B │ ●─┼──>│ C │ ●─┼──>│ D │ │
└───┴───┘ └───┴───┘ └───┴───┘ └───┴───┘
我们来比较一下 ArrayList 和 LinkedList:
| ArrayList | LinkedList | |
|---|---|---|
| 获取指定元素 | 速度很快 | 需要从头开始查找元素 |
| 添加元素到末尾 | 速度很快 | 速度很快 |
| 在指定位置添加 / 删除 | 需要移动元素 | 不需要移动元素 |
| 内存占用 | 少 | 较大 |
| 通常情况下,我们总是优先使用 ArrayList。 |
使用 List 时,我们要关注 List 接口的规范。List 接口允许我们添加重复的元素,即 List 内部的元素可以重复:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("apple"); // size=1
list.add("pear"); // size=2
list.add("apple"); // 允许重复添加元素,size=3
System.out.println(list.size());
}
}
List 还允许添加 null:
1
2
3
4
5
6
7
8
9
10public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple"); // size=1
list.add(null); // size=2
list.add("pear"); // size=3
String second = list.get(1); // null
System.out.println(second);
}
}
除了使用 ArrayList 和 LinkedList,我们还可以通过 List 接口提供的 of() 方法,根据给定元素快速创建 List:
除了使用 ArrayList 和 LinkedList,我们还可以通过 List 接口提供的 of() 方法,根据给定元素快速创建 List:
1
List<Integer> list = List.of(1, 2, 5);
但是 List.of() 方法不接受 null 值,如果传入 null,会抛出 NullPointerException 异常。
和数组类型,我们要遍历一个 List,完全可以用 for 循环根据索引配合 get(int) 方法遍历:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (int i=0; i<list.size(); i++) {
String s = list.get(i);
System.out.println(s);
}
}
}
但这种方式并不推荐,一是代码复杂,二是因为get(int)方法只有ArrayList的实现是高效的,换成LinkedList后,索引越大,访问速度越慢。
所以我们要始终坚持使用迭代器Iterator来访问List。Iterator本身也是一个对象,但它是由List的实例调用iterator()方法的时候创建的。Iterator对象知道如何遍历一个List,并且不同的List类型,返回的Iterator对象实现也是不同的,但总是具有最高的访问效率。
Iterator对象有两个方法:boolean hasNext()判断是否有下一个元素,E next()返回下一个元素。因此,使用Iterator遍历List代码如下:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
System.out.println(s);
}
}
}
有童鞋可能觉得使用 Iterator 访问 List 的代码比使用索引更复杂。但是,要记住,通过 Iterator 遍历 List 永远是最高效的方式。并且,由于 Iterator 遍历是如此常用,所以,Java 的 for each 循环本身就可以帮我们使用 Iterator 遍历。把上面的代码再改写如下:
1
2
3
4
5
6
7
8public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
for (String s : list) {
System.out.println(s);
}
}
}
上述代码就是我们编写遍历 List 的常见代码。
实际上,只要实现了 Iterable 接口的集合类都可以直接用 for each 循环来遍历,Java 编译器本身并不知道如何遍历集合对象,但它会自动把 for each 循环变成 Iterator 的调用,原因就在于 Iterable 接口定义了一个 Iterator<E> iterator() 方法,强迫集合类必须返回一个 Iterator 实例。
Note: Java的
for - each遍历不是只读的。
把List变为Array有三种方法,第一种是调用toArray()方法直接返回一个Object[]数组:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
List<String> list = List.of("apple", "pear", "banana");
Object[] array = list.toArray();
for (Object s : array) {
System.out.println(s);
}
}
}
这种方法会丢失类型信息,所以实际应用很少。
第二种方式是给 toArray(T[]) 传入一个类型相同的 Array,List 内部自动把元素复制到传入的 Array 中:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
List<Integer> list = List.of(12, 34, 56);
Integer[] array = list.toArray(new Integer[3]);
for (Integer n : array) {
System.out.println(n);
}
}
}
注意到这个 toArray(T[]) 方法的泛型参数 <T> 并不是 List 接口定义的泛型参数 <E>,所以,我们实际上可以传入其他类型的数组,例如我们传入 Number 类型的数组,返回的仍然是 Number 类型:
注意到这个 toArray(T[]) 方法的泛型参数 <T> 并不是 List 接口定义的泛型参数 <E>,所以,我们实际上可以传入其他类型的数组,例如我们传入 Number 类型的数组,返回的仍然是 Number 类型:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
List<Integer> list = List.of(12, 34, 56);
Number[] array = list.toArray(new Number[3]);
for (Number n : array) {
System.out.println(n);
}
}
}
但是,如果我们传入类型不匹配的数组,例如,String[]类型的数组,由于 List 的元素是 Integer,所以无法放入 String 数组,这个方法会抛出 ArrayStoreException。
如果我们传入的数组大小和 List 实际的元素个数不一致怎么办?根据 List 接口的文档,我们可以知道:
如果传入的数组不够大,那么 List 内部会创建一个新的刚好够大的数组,填充后返回;如果传入的数组比 List 元素还要多,那么填充完元素后,剩下的数组元素一律填充 null。
实际上,最常用的是传入一个 “恰好” 大小的数组:
1
Integer[] array = list.toArray(new Integer[list.size()]);
最后一种更简洁的写法是通过 List 接口定义的 T[] toArray(IntFunction<T[]> generator) 方法:
1
Integer[] array = list.toArray(Integer[]::new);
这种函数式写法我们会在后续讲到。
反过来,把Array变为List就简单多了,通过List.of(T…)方法最简单:
1
2Integer[] array = { 1, 2, 3 };
List<Integer> list = List.of(array);
对于 JDK 11 之前的版本,可以使用 Arrays.asList(T...) 方法把数组转换成 List。
要注意的是,返回的 List 不一定就是 ArrayList 或者 LinkedList,因为 List 只是一个接口,如果我们调用 List.of(),它返回的是一个只读 List:
1
2
3
4
5
6public class Main {
public static void main(String[] args) {
List<Integer> list = List.of(12, 34, 56);
list.add(999); // UnsupportedOperationException
}
}
对只读 List 调用 add()、remove() 方法会抛出 UnsupportedOperationException。
List 还提供了 boolean contains(Object o) 方法来判断 List 是否包含某个指定元素。此外,int indexOf(Object o) 方法可以返回某个元素的索引,如果元素不存在,就返回 -1。
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
List<String> list = List.of("A", "B", "C");
System.out.println(list.contains("C")); // true
System.out.println(list.contains("X")); // false
System.out.println(list.indexOf("C")); // 2
System.out.println(list.indexOf("X")); // -1
}
}
这里我们注意一个问题,我们往List中添加的"C"和调用contains("C")传入的"C"是不是同一个实例?
如果这两个"C"不是同一个实例,这段代码是否还能得到正确的结果?我们可以改写一下代码测试一下:
1
2
3
4
5
6
7
8import java.util.List;
public class Main {
public static void main(String[] args) {
List<String> list = List.of("A", "B", "C");
System.out.println(list.contains(new String("C"))); // true or false?
System.out.println(list.indexOf(new String("C"))); // 2 or -1?
}
}
因为我们传入的是new String("C"),所以一定是不同的实例。结果仍然符合预期,这是为什么呢?
因为List内部并不是通过==判断两个元素是否相等,而是使用equals()方法判断两个元素是否相等,例如contains()方法可以实现如下:
1
2
3
4
5
6
7
8
9
10
11public class ArrayList {
Object[] elementData;
public boolean contains(Object o) {
for (int i = 0; i < size; i++) {
if (o.equals(elementData[i])) {
return true;
}
}
return false;
}
}
因此,要正确使用List的contains()、indexOf()这些方法,放入的实例必须正确覆写equals()方法,否则,放进去的实例,查找不到。我们之所以能正常放入String、Integer这些对象,是因为Java标准库定义的这些类已经正确实现了equals()方法。
我们以Person对象为例,测试一下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import java.util.List;
public class Main {
public static void main(String[] args) {
List<Person> list = List.of(
new Person("Xiao Ming"),
new Person("Xiao Hong"),
new Person("Bob")
);
System.out.println(list.contains(new Person("Bob"))); // false
}
}
class Person {
String name;
public Person(String name) {
this.name = name;
}
}
不出意外,虽然放入了new Person("Bob"),但是用另一个new Person("Bob")查询不到,原因就是Person类没有覆写equals()方法。
JAVA当中所有的类都是继承于Object这个超类的,在Object类中定义了一个equals的方法,equals的源码是这样写的:
1
2
3
4
5public boolean equals(Object obj) {
//this - s1
//obj - s2
return (this == obj);
}
可以看到,这个方法的初始默认行为是比较对象的内存地址值,一般来说,意义不大。所以,在一些类库当中这个方法被重写了,如String、Integer、Date。在这些类当中equals有其自身的实现(一般都是用来比较对象的成员变量值是否相同),而不再是比较类在堆内存中的存放地址了。
如何正确编写equals()方法?equals()方法要求我们必须满足以下条件:
x.equals(x) 必须返回 true;x.equals(y) 为 true,则 y.equals(x) 也必须为 true;x.equals(y) 为 true,y.equals(z) 也为 true,那么 x.equals(z) 也必须为 true;x.equals(y) 总是一致地返回 true 或者 false;x.equals(null) 永远返回 false。 上述规则看上去似乎非常复杂,但其实代码实现equals()方法是很简单的,我们以Person类为例:
1
2
3
4public class Person {
public String name;
public int age;
}
首先,我们要定义“相等”的逻辑含义。对于Person类,如果name相等,并且age相等,我们就认为两个Person实例相等。
因此,编写equals()方法如下:
1
2
3
4
5
6
7public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
return this.name.equals(p.name) && this.age == p.age;
}
return false;
}
对于引用字段比较,我们使用equals(),对于基本类型字段的比较,我们使用==。
如果this.name为null,那么equals()方法会报错,因此,需要继续改写如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public boolean equals(Object o) {
if (o instanceof Person) {
Person p = (Person) o;
boolean nameEquals = false;
if (this.name == null && p.name == null) {
nameEquals = true;
}
if (this.name != null) {
nameEquals = this.name.equals(p.name);
}
return nameEquals && this.age == p.age;
}
return false;
}
因此,我们总结一下equals()方法的正确编写方法:
instanceof判断传入的待比较的Object是不是当前类型,如果是,继续比较,否则,返回false;Objects.equals()比较,对基本类型直接用==比较。 使用Objects.equals()比较两个引用类型是否相等的目的是省去了判断null的麻烦。两个引用类型都是null时它们也是相等的。
如果不调用List的contains()、indexOf()这些方法,那么放入的元素就不需要实现equals()方法。
我们知道,List是一种顺序列表,如果有一个存储学生Student实例的List,要在List中根据name查找某个指定的Student的分数,应该怎么办?
最简单的方法是遍历List并判断name是否相等,然后返回指定元素:
1
2
3
4
5
6
7
8
9List<Student> list = ...
Student target = null;
for (Student s : list) {
if ("Xiao Ming".equals(s.name)) {
target = s;
break;
}
}
System.out.println(target.score);
这种需求其实非常常见,即通过一个键去查询对应的值。使用List来实现存在效率非常低的问题,因为平均需要扫描一半的元素才能确定,而Map这种键值(key-value)映射表的数据结构,作用就是能高效通过key快速查找value(元素)。
用Map来实现根据name查询某个Student的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Student s = new Student("Xiao Ming", 99);
Map<String, Student> map = new HashMap<>();
map.put("Xiao Ming", s); // 将"Xiao Ming"和Student实例映射并关联
Student target = map.get("Xiao Ming"); // 通过key查找并返回映射的Student实例
System.out.println(target == s); // true,同一个实例
System.out.println(target.score); // 99
Student another = map.get("Bob"); // 通过另一个key查找
System.out.println(another); // 未找到返回null
}
}
class Student {
public String name;
public int score;
public Student(String name, int score) {
this.name = name;
this.score = score;
}
}
通过上述代码可知:Map<K, V>是一种键-值映射表,当我们调用put(K key, V value)方法时,就把key和value做了映射并放入Map。当我们调用V get(K key)时,就可以通过key获取到对应的value。如果key不存在,则返回null。和List类似,Map也是一个接口,最常用的实现类是HashMap。
如果只是想查询某个key是否存在,可以调用boolean containsKey(K key)方法。
如果我们在存储Map映射关系的时候,对同一个key调用两次put()方法,分别放入不同的value,会有什么问题呢?例如:
1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
System.out.println(map.get("apple")); // 123
map.put("apple", 789); // 再次放入apple作为key,但value变为789
System.out.println(map.get("apple")); // 789
}
}
重复放入key-value并不会有任何问题,但是一个key只能关联一个value。在上面的代码中,一开始我们把key对象”apple”映射到Integer对象123,然后再次调用put()方法把”apple”映射到789,这时,原来关联的value对象123就被“冲掉”了。实际上,put()方法的签名是V put(K key, V value),如果放入的key已经存在,put()方法会返回被删除的旧的value,否则,返回null。
始终牢记:Map中不存在重复的key,因为放入相同的key,只会把原有的key-value对应的value给替换掉。
此外,在一个Map中,虽然key不能重复,但value是可以重复的:
1
2
3Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 123); // ok
对Map来说,要遍历key可以使用for each循环遍历Map实例的keySet()方法返回的Set集合,它包含不重复的key的集合:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (String key : map.keySet()) {
Integer value = map.get(key);
System.out.println(key + " = " + value);
}
}
}
同时遍历key和value可以使用for each循环遍历Map对象的entrySet()集合,它包含每一个key-value映射:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 123);
map.put("pear", 456);
map.put("banana", 789);
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println(key + " = " + value);
}
}
}
Map和List不同的是,Map存储的是key-value的映射关系,并且,它不保证顺序。在遍历的时候,遍历的顺序既不一定是put()时放入的key的顺序,也不一定是key的排序顺序。使用Map时,任何依赖顺序的逻辑都是不可靠的。以HashMap为例,假设我们放入”A”,”B”,”C”这3个key,遍历的时候,每个key会保证被遍历一次且仅遍历一次,但顺序完全没有保证,甚至对于不同的JDK版本,相同的代码遍历的输出顺序都是不同的!
遍历Map时,不可假设输出的key是有序的!
Map是一种键-值(key-value)映射表,可以通过key快速查找对应的value。
以HashMap为例,观察下面的代码:
1
2
3
4
5
6
7Map<String, Person> map = new HashMap<>();
map.put("a", new Person("Xiao Ming"));
map.put("b", new Person("Xiao Hong"));
map.put("c", new Person("Xiao Jun"));
map.get("a"); // Person("Xiao Ming")
map.get("x"); // null
HashMap之所以能根据key直接拿到value,原因是它内部通过空间换时间的方法,用一个大数组存储所有value,并根据key直接计算出value应该存储在哪个索引:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 ┌───┐
0 │ │
├───┤
1 │ ●─┼───> Person("Xiao Ming")
├───┤
2 │ │
├───┤
3 │ │
├───┤
4 │ │
├───┤
5 │ ●─┼───> Person("Xiao Hong")
├───┤
6 │ ●─┼───> Person("Xiao Jun")
├───┤
7 │ │
└───┘
如果key的值为”a”,计算得到的索引总是1,因此返回value为Person(“Xiao Ming”),如果key的值为”b”,计算得到的索引总是5,因此返回value为Person(“Xiao Hong”),这样,就不必遍历整个数组,即可直接读取key对应的value。
当我们使用key存取value的时候,就会引出一个问题:
我们放入Map的key是字符串”a”,但是,当我们获取Map的value时,传入的变量不一定就是放入的那个key对象。
换句话讲,两个key应该是内容相同,但不一定是同一个对象。测试代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import java.util.HashMap;
import java.util.Map;
public class Main {
public static void main(String[] args) {
String key1 = "a";
Map<String, Integer> map = new HashMap<>();
map.put(key1, 123);
String key2 = new String("a");
map.get(key2); // 123
System.out.println(key1 == key2); // false
System.out.println(key1.equals(key2)); // true
}
}
因为在Map的内部,对key做比较是通过equals()实现的,这一点和List查找元素需要正确覆写equals()是一样的,即正确使用Map必须保证:作为key的对象必须正确覆写equals()方法。
我们经常使用String作为key,因为String已经正确覆写了equals()方法。但如果我们放入的key是一个自己写的类,就必须保证正确覆写了equals()方法。
我们再思考一下HashMap为什么能通过key直接计算出value存储的索引。相同的key对象(使用equals()判断时返回true)必须要计算出相同的索引,否则,相同的key每次取出的value就不一定对。
通过key计算索引的方式就是调用key对象的hashCode()方法,它返回一个int整数。HashMap正是通过这个方法直接定位key对应的value的索引,继而直接返回value。
因此,正确使用Map必须保证:
即对应两个实例a和b:
上述第一条规范是正确性,必须保证实现,否则HashMap不能正常工作。
而第二条如果尽量满足,则可以保证查询效率,因为不同的对象,如果返回相同的hashCode(),会造成Map内部存储冲突,使存取的效率下降。
正确编写equals()的方法我们已经在编写equals方法一节中讲过了。
在正确实现equals()的基础上,我们还需要正确实现hashCode(),即上述3个字段分别相同的实例,hashCode()返回的int必须相同:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Person {
String firstName;
String lastName;
int age;
int hashCode() {
int h = 0;
h = 31 * h + firstName.hashCode();
h = 31 * h + lastName.hashCode();
h = 31 * h + age;
return h;
}
}
注意到String类已经正确实现了hashCode()方法,我们在计算Person的hashCode()时,反复使用31*h,这样做的目的是为了尽量把不同的Person实例的hashCode()均匀分布到整个int范围。
和实现equals()方法遇到的问题类似,如果firstName或lastName为null,上述代码工作起来就会抛NullPointerException。为了解决这个问题,我们在计算hashCode()的时候,经常借助Objects.hash()来计算:
1
2
3int hashCode() {
return Objects.hash(firstName, lastName, age);
}
所以,编写equals()和hashCode()遵循的原则是:
equals()用到的用于比较的每一个字段,都必须在hashCode()中用于计算;equals()中没有使用到的字段,绝不可放在hashCode()中计算。
另外注意,对于放入HashMap的value对象,没有任何要求。
既然HashMap内部使用了数组,通过计算key的hashCode()直接定位value所在的索引,那么第一个问题来了:hashCode()返回的int范围高达±21亿,先不考虑负数,HashMap内部使用的数组得有多大?
实际上HashMap初始化时默认的数组大小只有16,任何key,无论它的hashCode()有多大,都可以简单地通过:
1
int index = key.hashCode() & 0xf; // 0xf = 15
把索引确定在0~15,即永远不会超出数组范围,上述算法只是一种最简单的实现。
第二个问题:如果添加超过16个key-value到HashMap,数组不够用了怎么办?
添加超过一定数量的key-value时,HashMap会在内部自动扩容,每次扩容一倍,即长度为16的数组扩展为长度32,相应地,需要重新确定hashCode()计算的索引位置。例如,对长度为32的数组计算hashCode()对应的索引,计算方式要改为:
1
int index = key.hashCode() & 0x1f; // 0x1f = 31
由于扩容会导致重新分布已有的key-value,所以,频繁扩容对HashMap的性能影响很大。如果我们确定要使用一个容量为10000个key-value的HashMap,更好的方式是创建HashMap时就指定容量:
1
Map<String, Integer> map = new HashMap<>(10000);
虽然指定容量是10000,但HashMap内部的数组长度总是2n,因此,实际数组长度被初始化为比10000大的16384($2^{14}$)。
最后一个问题:如果不同的两个key,例如”a”和”b”,它们的hashCode()恰好是相同的(这种情况是完全可能的,因为不相等的两个实例,只要求hashCode()尽量不相等),那么,当我们放入:
1
2map.put("a", new Person("Xiao Ming"));
map.put("b", new Person("Xiao Hong"));
时,由于计算出的数组索引相同,后面放入的”Xiao Hong”会不会把”Xiao Ming”覆盖了?
当然不会!使用Map的时候,只要key不相同,它们映射的value就互不干扰。但是,在HashMap内部,确实可能存在不同的key,映射到相同的hashCode(),即相同的数组索引上,肿么办?
我们就假设”a”和”b”这两个key最终计算出的索引都是5,那么,在HashMap的数组中,实际存储的不是一个Person实例,而是一个List,它包含两个Entry,一个是”a”的映射,一个是”b”的映射:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17 ┌───┐
0 │ │
├───┤
1 │ │
├───┤
2 │ │
├───┤
3 │ │
├───┤
4 │ │
├───┤
5 │ ●─┼───> List<Entry<String, Person>>
├───┤
6 │ │
├───┤
7 │ │
└───┘
在查找的时候,例如:
1
Person p = map.get("a");
HashMap内部通过”a”找到的实际上是List<Entry<String, Person>>,它还需要遍历这个List,并找到一个Entry,它的key字段是”a”,才能返回对应的Person实例。
我们把不同的key具有相同的hashCode()的情况称之为哈希冲突。在冲突的时候,一种最简单的解决办法是用List存储hashCode()相同的key-value。显然,如果冲突的概率越大,这个List就越长,Map的get()方法效率就越低,这就是为什么要尽量满足条件二:
如果两个对象不相等,则两个对象的hashCode()尽量不要相等。
hashCode()方法编写得越好,HashMap工作的效率就越高。
因为HashMap是一种通过对key计算hashCode(),通过空间换时间的方式,直接定位到value所在的内部数组的索引,因此,查找效率非常高。
如果作为key的对象是enum类型,那么,还可以使用Java集合库提供的一种EnumMap,它在内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
我们以DayOfWeek这个枚举类型为例,为它做一个“翻译”功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import java.time.DayOfWeek;
import java.util.*;
public class Main {
public static void main(String[] args) {
Map<DayOfWeek, String> map = new EnumMap<>(DayOfWeek.class);
map.put(DayOfWeek.MONDAY, "星期一");
map.put(DayOfWeek.TUESDAY, "星期二");
map.put(DayOfWeek.WEDNESDAY, "星期三");
map.put(DayOfWeek.THURSDAY, "星期四");
map.put(DayOfWeek.FRIDAY, "星期五");
map.put(DayOfWeek.SATURDAY, "星期六");
map.put(DayOfWeek.SUNDAY, "星期日");
System.out.println(map);
System.out.println(map.get(DayOfWeek.MONDAY));
}
}
使用EnumMap的时候,我们总是用Map接口来引用它,因此,实际上把HashMap和EnumMap互换,在客户端看来没有任何区别。
我们已经知道,HashMap是一种以空间换时间的映射表,它的实现原理决定了内部的Key是无序的,即遍历HashMap的Key时,其顺序是不可预测的(但每个Key都会遍历一次且仅遍历一次)。
还有一种Map,它在内部会对Key进行排序,这种Map就是SortedMap。注意到SortedMap是接口,它的实现类是TreeMap。
1
2
3
4
5
6
7
8
9
10
11
12
13
14 ┌───┐
│Map│
└───┘
▲
┌────┴─────┐
│ │
┌───────┐ ┌─────────┐
│HashMap│ │SortedMap│
└───────┘ └─────────┘
▲
│
┌─────────┐
│ TreeMap │
└─────────┘
SortedMap保证遍历时以Key的顺序来进行排序。例如,放入的Key是”apple”、”pear”、”orange”,遍历的顺序一定是”apple”、”orange”、”pear”,因为String默认按字母排序:
1
2
3
4
5
6
7
8
9
10
11
12
13
14import java.util.*;
public class Main {
public static void main(String[] args) {
Map<String, Integer> map = new TreeMap<>();
map.put("orange", 1);
map.put("apple", 2);
map.put("pear", 3);
for (String key : map.keySet()) {
System.out.println(key);
}
// apple, orange, pear
}
}
使用TreeMap时,放入的Key必须实现Comparable接口。String、Integer这些类已经实现了Comparable接口,因此可以直接作为Key使用。作为Value的对象则没有任何要求。
如果作为Key的class没有实现Comparable接口,那么,必须在创建TreeMap时同时指定一个自定义排序算法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28import java.util.*;
public class Main {
public static void main(String[] args) {
Map<Person, Integer> map = new TreeMap<>(new Comparator<Person>() {
public int compare(Person p1, Person p2) {
return p1.name.compareTo(p2.name);
}
});
map.put(new Person("Tom"), 1);
map.put(new Person("Bob"), 2);
map.put(new Person("Lily"), 3);
for (Person key : map.keySet()) {
System.out.println(key);
}
// {Person: Bob}, {Person: Lily}, {Person: Tom}
System.out.println(map.get(new Person("Bob"))); // 2
}
}
class Person {
public String name;
Person(String name) {
this.name = name;
}
public String toString() {
return "{Person: " + name + "}";
}
}
注意到Comparator接口要求实现一个比较方法,它负责比较传入的两个元素a和b,如果a<b,则返回负数,通常是-1,如果a==b,则返回0,如果a>b,则返回正数,通常是1。TreeMap内部根据比较结果对Key进行排序。
从上述代码执行结果可知,打印的Key确实是按照Comparator定义的顺序排序的。如果要根据Key查找Value,我们可以传入一个new Person(“Bob”)作为Key,它会返回对应的Integer值2。
另外,注意到Person类并未覆写equals()和hashCode(),**因为TreeMap不使用equals()和hashCode()**。
我们来看一个稍微复杂的例子:这次我们定义了Student类,并用分数score进行排序,高分在前:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import java.util.*;
public class Main {
public static void main(String[] args) {
Map<Student, Integer> map = new TreeMap<>(new Comparator<Student>() {
public int compare(Student p1, Student p2) {
return p1.score > p2.score ? -1 : 1;
}
});
map.put(new Student("Tom", 77), 1);
map.put(new Student("Bob", 66), 2);
map.put(new Student("Lily", 99), 3);
for (Student key : map.keySet()) {
System.out.println(key);
}
System.out.println(map.get(new Student("Bob", 66))); // null?
}
}
class Student {
public String name;
public int score;
Student(String name, int score) {
this.name = name;
this.score = score;
}
public String toString() {
return String.format("{%s: score=%d}", name, score);
}
}
在for循环中,我们确实得到了正确的顺序。但是,且慢!根据相同的Key:new Student("Bob", 66)进行查找时,结果为null!
这是怎么肥四?难道TreeMap有问题?遇到TreeMap工作不正常时,我们首先回顾Java编程基本规则:出现问题,不要怀疑Java标准库,要从自身代码找原因。
在这个例子中,TreeMap出现问题,原因其实出在这个Comparator上:
1
2
3public int compare(Student p1, Student p2) {
return p1.score > p2.score ? -1 : 1;
}
在p1.score和p2.score不相等的时候,它的返回值是正确的,但是,在p1.score和p2.score相等的时候,它并没有返回0!这就是为什么TreeMap工作不正常的原因:TreeMap在比较两个Key是否相等时,依赖Key的compareTo()方法或者Comparator.compare()方法。在两个Key相等时,必须返回0。因此,修改代码如下:
1
2
3
4
5
6public int compare(Student p1, Student p2) {
if (p1.score == p2.score) {
return 0;
}
return p1.score > p2.score ? -1 : 1;
}
或者直接借助Integer.compare(int, int)也可以返回正确的比较结果。
在编写应用程序的时候,经常需要读写配置文件。例如,用户的设置:
1
2
3
4# 上次最后打开的文件:
last_open_file=/data/hello.txt
# 自动保存文件的时间间隔:
auto_save_interval=60
配置文件的特点是,它的Key-Value一般都是String-String类型的,因此我们完全可以用Map<String, String>来表示它。
因为配置文件非常常用,所以Java集合库提供了一个Properties来表示一组“配置”。由于历史遗留原因,Properties内部本质上是一个Hashtable,但我们只需要用到Properties自身关于读写配置的接口。
用Properties读取配置文件非常简单。Java默认配置文件以.properties为扩展名,每行以key=value表示,以#课开头的是注释。以下是一个典型的配置文件:
1
2
3
4# setting.properties
last_open_file=/data/hello.txt
auto_save_interval=60
可以从文件系统读取这个.properties文件:
1
2
3
4
5
6String f = "setting.properties";
Properties props = new Properties();
props.load(new java.io.FileInputStream(f));
String filepath = props.getProperty("last_open_file");
String interval = props.getProperty("auto_save_interval", "120");
可见,用Properties读取配置文件,一共有三步:
调用getProperty()获取配置时,如果key不存在,将返回null。我们还可以提供一个默认值,这样,当key不存在的时候,就返回默认值。
也可以从classpath读取.properties文件,因为load(InputStream)方法接收一个InputStream实例,表示一个字节流,它不一定是文件流,也可以是从jar包中读取的资源流:
1
2Properties props = new Properties();
props.load(getClass().getResourceAsStream("/common/setting.properties"));
试试从内存读取一个字节流:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import java.io.*;
import java.util.Properties;
public class Main {
public static void main(String[] args) throws IOException {
String settings = "# test" + "\n" + "course=Java" + "\n" + "last_open_date=2019-08-07T12:35:01";
ByteArrayInputStream input = new ByteArrayInputStream(settings.getBytes("UTF-8"));
Properties props = new Properties();
props.load(input);
System.out.println("course: " + props.getProperty("course"));
System.out.println("last_open_date: " + props.getProperty("last_open_date"));
System.out.println("last_open_file: " + props.getProperty("last_open_file"));
System.out.println("auto_save: " + props.getProperty("auto_save", "60"));
}
}
如果有多个.properties文件,可以反复调用load()读取,后读取的key-value会覆盖已读取的key-value:
1
2
3Properties props = new Properties();
props.load(getClass().getResourceAsStream("/common/setting.properties"));
props.load(new FileInputStream("C:\\conf\\setting.properties"));
上面的代码演示了Properties的一个常用用法:可以把默认配置文件放到classpath中,然后,根据机器的环境编写另一个配置文件,覆盖某些默认的配置。
Properties设计的目的是存储String类型的key-value,但Properties实际上是从Hashtable派生的,它的设计实际上是有问题的,但是为了保持兼容性,现在已经没法修改了。除了getProperty()和setProperty()方法外,还有从Hashtable继承下来的get()和put()方法,这些方法的参数签名是Object,我们在使用Properties的时候,不要去调用这些从Hashtable继承下来的方法。
如果通过setProperty()修改了Properties实例,可以把配置写入文件,以便下次启动时获得最新配置。写入配置文件使用store()方法:
1
2
3
4Properties props = new Properties();
props.setProperty("url", "http://www.liaoxuefeng.com");
props.setProperty("language", "Java");
props.store(new FileOutputStream("C:\\conf\\setting.properties"), "这是写入的properties注释");
早期版本的Java规定.properties文件编码是ASCII编码(ISO8859-1),如果涉及到中文就必须用name=\u4e2d\u6587来表示,非常别扭。从JDK9开始,Java的.properties文件可以使用UTF-8编码了。
不过,需要注意的是,由于load(InputStream)默认总是以ASCII编码读取字节流,所以会导致读到乱码。我们需要用另一个重载方法load(Reader)读取:
1
2Properties props = new Properties();
props.load(new FileReader("settings.properties", StandardCharsets.UTF_8));
就可以正常读取中文。InputStream和Reader的区别是一个是字节流,一个是字符流。字符流在内存中已经以char类型表示了,不涉及编码问题。
我们知道,Map用于存储key-value的映射,对于充当key的对象,是不能重复的,并且,不但需要正确覆写equals()方法,还要正确覆写hashCode()方法。
如果我们只需要存储不重复的key,并不需要存储映射的value,那么就可以使用Set。
Set用于存储不重复的元素集合,它主要提供以下几个方法:
Set<E>:boolean add(E e)Set<E>删除:boolean remove(Object e)boolean contains(Object e) 我们来看几个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.*;
public class Main {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
System.out.println(set.add("abc")); // true
System.out.println(set.add("xyz")); // true
System.out.println(set.add("xyz")); // false,添加失败,因为元素已存在
System.out.println(set.contains("xyz")); // true,元素存在
System.out.println(set.contains("XYZ")); // false,元素不存在
System.out.println(set.remove("hello")); // false,删除失败,因为元素不存在
System.out.println(set.size()); // 2,一共两个元素
}
}
Set实际上相当于只存储key、不存储value的Map。我们经常用Set用于去除重复元素。
因为放入Set的元素和Map的key类似,都要正确实现equals()和hashCode()方法,否则该元素无法正确地放入Set。
最常用的Set实现类是HashSet,实际上,HashSet仅仅是对HashMap的一个简单封装,它的核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class HashSet<E> implements Set<E> {
// 持有一个HashMap:
private HashMap<E, Object> map = new HashMap<>();
// 放入HashMap的value:
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT) == null;
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean remove(Object o) {
return map.remove(o) == PRESENT;
}
}
Set接口并不保证有序,而SortedSet接口则保证元素是有序的:
用一张图表示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14 ┌───┐
│Set│
└───┘
▲
┌────┴─────┐
│ │
┌───────┐ ┌─────────┐
│HashSet│ │SortedSet│
└───────┘ └─────────┘
▲
│
┌─────────┐
│ TreeSet │
└─────────┘
我们来看HashSet的输出:
1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.*;
public class Main {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
set.add("apple");
set.add("banana");
set.add("pear");
set.add("orange");
for (String s : set) {
System.out.println(s);
}
}
}
注意输出的顺序既不是添加的顺序,也不是String排序的顺序,在不同版本的JDK中,这个顺序也可能是不同的。
把HashSet换成TreeSet,在遍历TreeSet时,输出就是有序的,这个顺序是元素的排序顺序:
1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.*;
public class Main {
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("apple");
set.add("banana");
set.add("pear");
set.add("orange");
for (String s : set) {
System.out.println(s);
}
}
}
使用TreeSet和使用TreeMap的要求一样,添加的元素必须正确实现Comparable接口,如果没有实现Comparable接口,那么创建TreeSet时必须传入一个Comparator对象。
队列(Queue)是一种经常使用的集合。Queue实际上是实现了一个先进先出(FIFO:First In First Out)的有序表。它和List的区别在于,List可以在任意位置添加和删除元素,而Queue只有两个操作:
例如:超市的收银台就是一个队列
在Java的标准库中,队列接口Queue定义了以下几个方法:
对于具体的实现类,有的Queue有最大队列长度限制,有的Queue没有。注意到添加、删除和获取队列元素总是有两个方法,这是因为在添加或获取元素失败时,这两个方法的行为是不同的。我们用一个表格总结如下:
| throw Exception | 返回false或null | |||
|---|---|---|---|---|
| 添加元素到队尾 | add(E e) | boolean offer(E e) | ||
| 取队首元素并删除 | E remove() | E poll() | ||
| 取队首元素但不删除 | E element() | E peek() | ||
| 举个栗子,假设我们有一个队列,对它做一个添加操作,如果调用add()方法,当添加失败时(可能超过了队列的容量),它会抛出异常: | ||||
|
||||
| 如果我们调用offer()方法来添加元素,当添加失败时,它不会抛异常,而是返回false: | ||||
|
||||
| 当我们需要从Queue中取出队首元素时,如果当前Queue是一个空队列,调用remove()方法,它会抛出异常: | ||||
|
||||
| 如果我们调用poll()方法来取出队首元素,当获取失败时,它不会抛异常,而是返回null: | ||||
|
||||
| 因此,两套方法可以根据需要来选择使用。 | ||||
| 注意:不要把null添加到队列中,否则poll()方法返回null时,很难确定是取到了null元素还是队列为空。 | ||||
| 接下来我们以poll()和peek()为例来说说“获取并删除”与“获取但不删除”的区别。对于Queue来说,每次调用poll(),都会获取队首元素,并且获取到的元素已经从队列中被删除了: | ||||
|
||||
| 如果用peek(),因为获取队首元素时,并不会从队列中删除这个元素,所以可以反复获取: | ||||
|
||||
| 从上面的代码中,我们还可以发现,LinkedList即实现了List接口,又实现了Queue接口,但是,在使用的时候,如果我们把它当作List,就获取List的引用,如果我们把它当作Queue,就获取Queue的引用: | ||||
|
||||
| 始终按照面向抽象编程的原则编写代码,可以大大提高代码的质量。 |
我们知道,Queue是一个先进先出(FIFO)的队列。
在银行柜台办业务时,我们假设只有一个柜台在办理业务,但是办理业务的人很多,怎么办?
可以每个人先取一个号,例如:A1、A2、A3……然后,按照号码顺序依次办理,实际上这就是一个Queue。
如果这时来了一个VIP客户,他的号码是V1,虽然当前排队的是A10、A11、A12……但是柜台下一个呼叫的客户号码却是V1。
这个时候,我们发现,要实现“VIP插队”的业务,用Queue就不行了,因为Queue会严格按FIFO的原则取出队首元素。我们需要的是优先队列:PriorityQueue。
PriorityQueue和Queue的区别在于,它的出队顺序与元素的优先级有关,对PriorityQueue调用remove()或poll()方法,返回的总是优先级最高的元素。
要使用PriorityQueue,我们就必须给每个元素定义“优先级”。我们以实际代码为例,先看看PriorityQueue的行为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import java.util.PriorityQueue;
import java.util.Queue;
public class Main {
public static void main(String[] args) {
Queue<String> q = new PriorityQueue<>();
// 添加3个元素到队列:
q.offer("apple");
q.offer("pear");
q.offer("banana");
System.out.println(q.poll()); // apple
System.out.println(q.poll()); // banana
System.out.println(q.poll()); // pear
System.out.println(q.poll()); // null,因为队列为空
}
}
我们放入的顺序是”apple”、”pear”、”banana”,但是取出的顺序却是”apple”、”banana”、”pear”,这是因为从字符串的排序看,”apple”排在最前面,”pear”排在最后面。
因此,放入PriorityQueue的元素,必须实现Comparable接口,PriorityQueue会根据元素的排序顺序决定出队的优先级。
如果我们要放入的元素并没有实现Comparable接口怎么办?PriorityQueue允许我们提供一个Comparator对象来判断两个元素的顺序。我们以银行排队业务为例,实现一个PriorityQueue:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class Main {
public static void main(String[] args) {
Queue<User> q = new PriorityQueue<>(new UserComparator());
// 添加3个元素到队列:
q.offer(new User("Bob", "A1"));
q.offer(new User("Alice", "A2"));
q.offer(new User("Boss", "V1"));
System.out.println(q.poll()); // Boss/V1
System.out.println(q.poll()); // Bob/A1
System.out.println(q.poll()); // Alice/A2
System.out.println(q.poll()); // null,因为队列为空
}
}
class UserComparator implements Comparator<User> {
public int compare(User u1, User u2) {
if (u1.number.charAt(0) == u2.number.charAt(0)) {
// 如果两人的号都是A开头或者都是V开头,比较号的大小:
return u1.number.compareTo(u2.number);
}
if (u1.number.charAt(0) == 'V') {
// u1的号码是V开头,优先级高:
return -1;
} else {
return 1;
}
}
}
实现PriorityQueue的关键在于提供的UserComparator对象,它负责比较两个元素的大小(较小的在前)。UserComparator总是把V开头的号码优先返回,只有在开头相同的时候,才比较号码大小。
上面的UserComparator的比较逻辑其实还是有问题的,它会把A10排在A2的前面,请尝试修复该错误。
我们知道,Queue是队列,只能一头进,另一头出。
如果把条件放松一下,允许两头都进,两头都出,这种队列叫双端队列(Double Ended Queue),学名Deque。
Java集合提供了接口Deque来实现一个双端队列,它的功能是:
| Queue | Deque | |
|---|---|---|
| 添加元素到队尾 | add(E e) / offer(E e) | addLast(E e) / offerLast(E e) |
| 取队首元素并删除 | E remove() / E poll() | E removeFirst() / E pollFirst() |
| 取队首元素但不删除 | E element() / E peek() | E getFirst() / E peekFirst() |
| 添加元素到队首 | 无 | addFirst(E e) / offerFirst(E e) |
| 取队尾元素并删除 | 无 | E removeLast() / E pollLast() |
| 取队尾元素但不删除 | 无 | E getLast() / E peekLast() |
对于添加元素到队尾的操作,Queue提供了add()/offer()方法,而Deque提供了addLast()/offerLast()方法。添加元素到对首、取队尾元素的操作在Queue中不存在,在Deque中由addFirst()/removeLast()等方法提供。
注意到Deque接口实际上扩展自Queue:
1
2
3public interface Deque<E> extends Queue<E> {
...
}
因此,Queue提供的add()/offer()方法在Deque中也可以使用,但是,使用Deque,最好不要调用offer(),而是调用offerLast():
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import java.util.Deque;
import java.util.LinkedList;
public class Main {
public static void main(String[] args) {
Deque<String> deque = new LinkedList<>();
deque.offerLast("A"); // A
deque.offerLast("B"); // A <- B
deque.offerFirst("C"); // C <- A <- B
System.out.println(deque.pollFirst()); // C, 剩下A <- B
System.out.println(deque.pollLast()); // B, 剩下A
System.out.println(deque.pollFirst()); // A
System.out.println(deque.pollFirst()); // null
}
}
如果直接写deque.offer(),我们就需要思考,offer()实际上是offerLast(),我们明确地写上offerLast(),不需要思考就能一眼看出这是添加到队尾。
因此,使用Deque,推荐总是明确调用offerLast()/offerFirst()或者pollFirst()/pollLast()方法。
Deque是一个接口,它的实现类有ArrayDeque和LinkedList。
我们发现LinkedList真是一个全能选手,它即是List,又是Queue,还是Deque。但是我们在使用的时候,总是用特定的接口来引用它,这是因为持有接口说明代码的抽象层次更高,而且接口本身定义的方法代表了特定的用途。
1
2
3
4
5
6// 不推荐的写法:
LinkedList<String> d1 = new LinkedList<>();
d1.offerLast("z");
// 推荐的写法:
Deque<String> d2 = new LinkedList<>();
d2.offerLast("z");
可见面向抽象编程的一个原则就是:尽量持有接口,而不是具体的实现类。
Deque实现了一个双端队列(Double Ended Queue),它可以:
栈(Stack)是一种后进先出(LIFO:Last In First Out)的数据结构。
什么是LIFO呢?我们先回顾一下Queue的特点FIFO:
1
2
3
4
5 ────────────────────────
(\(\ (\(\ (\(\ (\(\ (\(\
(='.') ─> (='.') (='.') (='.') ─> (='.')
O(_")") O(_")") O(_")") O(_")") O(_")")
────────────────────────
所谓FIFO,是最先进队列的元素一定最早出队列,而LIFO是最后进Stack的元素一定最早出Stack。如何做到这一点呢?只需要把队列的一端封死:
1
2
3
4
5 ───────────────────────────────┐
(\(\ (\(\ (\(\ (\(\ (\(\ │
(='.') <─> (='.') (='.') (='.') (='.')│
O(_")") O(_")") O(_")") O(_")") O(_")")│
───────────────────────────────┘
因此,Stack是这样一种数据结构:只能不断地往Stack中压入(push)元素,最后进去的必须最早弹出(pop)来:
Stack只有入栈和出栈的操作:
在Java中,我们用Deque可以实现Stack的功能:
为什么Java的集合类没有单独的Stack接口呢?因为有个遗留类名字就叫Stack,出于兼容性考虑,所以没办法创建Stack接口,只能用Deque接口来“模拟”一个Stack了。
当我们把Deque作为Stack使用时,注意只调用push()/pop()/peek()方法,不要调用addFirst()/removeFirst()/peekFirst()方法,这样代码更加清晰。
Stack在计算机中使用非常广泛,JVM在处理Java方法调用的时候就会通过栈这种数据结构维护方法调用的层次。例如:
1
2
3
4
5
6
7
8
9
10
11static void main(String[] args) {
foo(123);
}
static String foo(x) {
return "F-" + bar(x + 1);
}
static int bar(int x) {
return x << 2;
}
JVM会创建方法调用栈,每调用一个方法时,先将参数压栈,然后执行对应的方法;当方法返回时,返回值压栈,调用方法通过出栈操作获得方法返回值。
因为方法调用栈有容量限制,嵌套调用过多会造成栈溢出,即引发StackOverflowError:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
increase(1);
}
static int increase(int x) {
return increase(x) + 1;
}
}
我们再来看一个Stack的用途:对整数进行进制的转换就可以利用栈。
例如,我们要把一个int整数12500转换为十六进制表示的字符串。
Java的集合类都可以使用for each循环,List、Set和Queue会迭代每个元素,Map会迭代每个key。以List为例:
1
2
3
4List<String> list = List.of("Apple", "Orange", "Pear");
for (String s : list) {
System.out.println(s);
}
实际上,Java编译器并不知道如何遍历List。上述代码能够编译通过,只是因为编译器把for each循环通过Iterator改写为了普通的for循环:
1
2
3
4for (Iterator<String> it = list.iterator(); it.hasNext(); ) {
String s = it.next();
System.out.println(s);
}
我们把这种通过Iterator对象遍历集合的模式称为迭代器。
使用迭代器的好处在于,调用方总是以统一的方式遍历各种集合类型,而不必关系它们内部的存储结构。
例如,我们虽然知道ArrayList在内部是以数组形式存储元素,并且,它还提供了get(int)方法。虽然我们可以用for循环遍历:
1
2
3for (int i=0; i<list.size(); i++) {
Object value = list.get(i);
}
但是这样一来,调用方就必须知道集合的内部存储结构。并且,如果把ArrayList换成LinkedList,get(int)方法耗时会随着index的增加而增加。如果把ArrayList换成Set,上述代码就无法编译,因为Set内部没有索引。
用Iterator遍历就没有上述问题,因为Iterator对象是集合对象自己在内部创建的,它自己知道如何高效遍历内部的数据集合,调用方则获得了统一的代码,编译器才能把标准的for each循环自动转换为Iterator遍历。
如果我们自己编写了一个集合类,想要使用for each循环,只需满足以下条件:
这里的关键在于,集合类通过调用iterator()方法,返回一个Iterator对象,这个对象必须自己知道如何遍历该集合。
一个简单的Iterator示例如下,它总是以倒序遍历集合:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47import java.util.*;
public class Main {
public static void main(String[] args) {
ReverseList<String> rlist = new ReverseList<>();
rlist.add("Apple");
rlist.add("Orange");
rlist.add("Pear");
for (String s : rlist) {
System.out.println(s);
}
}
}
class ReverseList<T> implements Iterable<T> {
private List<T> list = new ArrayList<>();
public void add(T t) {
list.add(t);
}
public Iterator<T> iterator() {
return new ReverseIterator(list.size());
}
class ReverseIterator implements Iterator<T> {
int index;
ReverseIterator(int index) {
this.index = index;
}
public boolean hasNext() {
return index > 0;
}
public T next() {
index--;
return ReverseList.this.list.get(index);
}
}
}
虽然ReverseList和ReverseIterator的实现类稍微比较复杂,但是,注意到这是底层集合库,只需编写一次。而调用方则完全按for each循环编写代码,根本不需要知道集合内部的存储逻辑和遍历逻辑。
在编写Iterator的时候,我们通常可以用一个内部类来实现Iterator接口,这个内部类可以直接访问对应的外部类的所有字段和方法。例如,上述代码中,内部类ReverseIterator可以用ReverseList.this获得当前外部类的this引用,然后,通过这个this引用就可以访问ReverseList的所有字段和方法。
Collections是JDK提供的工具类,同样位于java.util包中。它提供了一系列静态方法,能更方便地操作各种集合。
注意Collections结尾多了一个s,不是Collection!
我们一般看方法名和参数就可以确认Collections提供的该方法的功能。例如,对于以下静态方法:
addAll()方法可以给一个Collection类型的集合添加若干元素。因为方法签名是Collection,所以我们可以传入List,Set等各种集合类型。
Collections提供了一系列方法来创建空集合:
List<T> emptyList()Map<K, V> emptyMap()Set<T> emptySet() 要注意到返回的空集合是不可变集合,无法向其中添加或删除元素。
此外,也可以用各个集合接口提供的of(T…)方法创建空集合。例如,以下创建空List的两个方法是等价的:
1
2List<String> list1 = List.of();
List<String> list2 = Collections.emptyList();
Collections提供了一系列方法来创建一个单元素集合:
List<T> singletonList(T o)Map<K, V> singletonMap(K key, V value)Set<T> singleton(T o) 要注意到返回的单元素集合也是不可变集合,无法向其中添加或删除元素。
此外,也可以用各个集合接口提供的of(T…)方法创建单元素集合。例如,以下创建单元素List的两个方法是等价的:
1
2List<String> list1 = List.of("apple");
List<String> list2 = Collections.singletonList("apple");
实际上,使用List.of(T...)更方便,因为它既可以创建空集合,也可以创建单元素集合,还可以创建任意个元素的集合:
1
2
3
4List<String> list1 = List.of(); // empty list
List<String> list2 = List.of("apple"); // 1 element
List<String> list3 = List.of("apple", "pear"); // 2 elements
List<String> list4 = List.of("apple", "pear", "orange"); // 3 elements
Collections可以对List进行排序。因为排序会直接修改List元素的位置,因此必须传入可变List:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import java.util.*;
public class Main {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("apple");
list.add("pear");
list.add("orange");
// 排序前:
System.out.println(list);
Collections.sort(list);
// 排序后:
System.out.println(list);
}
}
Collections提供了洗牌算法,即传入一个有序的List,可以随机打乱List内部元素的顺序,效果相当于让计算机洗牌:
1
2
3
4
5
6
7
8
9
10
11
12
13
14import java.util.*;
public class Main {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
for (int i=0; i<10; i++) {
list.add(i);
}
// 洗牌前:
System.out.println(list);
Collections.shuffle(list);
// 洗牌后:
System.out.println(list);
}
}
Collections还提供了一组方法把可变集合封装成不可变集合:
List<T> unmodifiableList(List<? extends T> list)Set<T> unmodifiableSet(Set<? extends T> set)Map<K, V> unmodifiableMap(Map<? extends K, ? extends V> m) 这种封装实际上是通过创建一个代理对象,拦截掉所有修改方法实现的。我们来看看效果:
1
2
3
4
5
6
7
8
9
10public class Main {
public static void main(String[] args) {
List<String> mutable = new ArrayList<>();
mutable.add("apple");
mutable.add("pear");
// 变为不可变集合:
List<String> immutable = Collections.unmodifiableList(mutable);
immutable.add("orange"); // UnsupportedOperationException!
}
}
然而,继续对原始的可变List进行增删是可以的,并且,会直接影响到封装后的“不可变”List:
1
2
3
4
5
6
7
8
9
10
11
12import java.util.*;
public class Main {
public static void main(String[] args) {
List<String> mutable = new ArrayList<>();
mutable.add("apple");
mutable.add("pear");
// 变为不可变集合:
List<String> immutable = Collections.unmodifiableList(mutable);
mutable.add("orange");
System.out.println(immutable);
}
}
因此,如果我们希望把一个可变List封装成不可变List,那么,返回不可变List后,最好立刻扔掉可变List的引用,这样可以保证后续操作不会意外改变原始对象,从而造成“不可变”List变化了:
1
2
3
4
5
6
7
8
9
10
11
12
13import java.util.*;
public class Main {
public static void main(String[] args) {
List<String> mutable = new ArrayList<>();
mutable.add("apple");
mutable.add("pear");
// 变为不可变集合:
List<String> immutable = Collections.unmodifiableList(mutable);
// 立刻扔掉mutable的引用:
mutable = null;
System.out.println(immutable);
}
}
Collections还提供了一组方法,可以把线程不安全的集合变为线程安全的集合:
List<T> synchronizedList(List<T> list)Set<T> synchronizedSet(Set<T> s)Map<K,V> synchronizedMap(Map<K,V> m)多线程的概念我们会在后面讲。因为从Java 5开始,引入了更高效的并发集合类,所以上述这几个同步方法已经没有什么用了。
Collections类提供了一组工具方法来方便使用集合类:
在讲解什么是泛型之前,我们先观察 Java 标准库提供的 ArrayList,它可以看作 “可变长度” 的数组,因为用起来比数组更方便。
实际上 ArrayList 内部就是一个 Object[]数组,配合存储一个当前分配的长度,就可以充当“可变数组”:
1
2
3
4
5
6
7public class ArrayList {
private Object[] array;
private int size;
public void add(Object e) {...}
public void remove(int index) {...}
public Object get(int index) {...}
}
如果用上述 ArrayList 存储 String 类型,会有这么几个缺点:
例如,代码必须这么写:
1
2
3
4ArrayList list = new ArrayList();
list.add("Hello");
// 获取到Object,必须强制转型为String:
String first = (String) list.get(0);
很容易出现ClassCastException,因为容易“误转型”:
1
2
3list.add(new Integer(123));
// ERROR: ClassCastException:
String second = (String) list.get(1);
要解决上述问题,我们可以为String单独编写一种ArrayList:
1
2
3
4
5
6
7public class StringArrayList {
private String[] array;
private int size;
public void add(String e) {...}
public void remove(int index) {...}
public String get(int index) {...}
}
这样一来,存入的必须是String,取出的也一定是String,不需要强制转型,因为编译器会强制检查放入的类型:
1
2
3
4
5StringArrayList list = new StringArrayList();
list.add("Hello");
String first = list.get(0);
// 编译错误: 不允许放入非String类型:
list.add(new Integer(123));
问题暂时解决。
然而,新的问题是,如果要存储Integer,还需要为Integer单独编写一种ArrayList:
1
2
3
4
5
6
7public class IntegerArrayList {
private Integer[] array;
private int size;
public void add(Integer e) {...}
public void remove(int index) {...}
public Integer get(int index) {...}
}
实际上,还需要为其他所有class单独编写一种ArrayList:
- LongArrayList
- DoubleArrayList
- PersonArrayList
- …
这是不可能的,JDK的class就有上千个,而且它还不知道其他人编写的class。
为了解决新的问题,我们必须把ArrayList变成一种模板:ArrayList<T>,代码如下:
1
2
3
4
5
6
7public class ArrayList<T> {
private T[] array;
private int size;
public void add(T e) {...}
public void remove(int index) {...}
public T get(int index) {...}
}
T可以是任何class。这样一来,我们就实现了:编写一次模版,可以创建任意类型的ArrayList:
1
2
3
4
5
6// 创建可以存储String的ArrayList:
ArrayList<String> strList = new ArrayList<String>();
// 创建可以存储Float的ArrayList:
ArrayList<Float> floatList = new ArrayList<Float>();
// 创建可以存储Person的ArrayList:
ArrayList<Person> personList = new ArrayList<Person>();
因此,泛型就是定义一种模板,例如ArrayList<T>,然后在代码中为用到的类创建对应的ArrayList<类型>:
1
ArrayList<String> strList = new ArrayList<String>();
由编译器针对类型作检查:
1
2
3
4strList.add("hello"); // OK
String s = strList.get(0); // OK
strList.add(new Integer(123)); // compile error!
Integer n = strList.get(0); // compile error!
这样一来,既实现了编写一次,万能匹配,又通过编译器保证了类型安全:这就是泛型。
在 Java 标准库中的 ArrayList<T> 实现了 List<T> 接口,它可以向上转型为 List<T>:
1
2
3
4public class ArrayList<T> implements List<T> {
...
}
List<String> list = new ArrayList<String>();
即类型 ArrayList<T> 可以向上转型为 List<T>。
要特别注意:不能把 ArrayList<Integer> 向上转型为 ArrayList<Number> 或 List
这是为什么呢?假设 ArrayList<Integer> 可以向上转型为 ArrayList
1
2
3
4
5
6
7
8
9
10// 创建ArrayList<Integer>类型:
ArrayList<Integer> integerList = new ArrayList<Integer>();
// 添加一个Integer:
integerList.add(new Integer(123));
// “向上转型”为ArrayList<Number>:
ArrayList<Number> numberList = integerList;
// 添加一个Float,因为Float也是Number:
numberList.add(new Float(12.34));
// 从ArrayList<Integer>获取索引为1的元素(即添加的Float):
Integer n = integerList.get(1); // ClassCastException!
我们把一个 ArrayList<Integer> 转型为 ArrayList<Number> 类型后,这个 ArrayList<Number> 就可以接受 Float 类型,因为 Float 是 Number 的子类。但是,ArrayList<Number> 实际上和 ArrayList<Integer> 是同一个对象,也就是 ArrayList<Integer> 类型,它不可能接受 Float 类型, 所以在获取 Integer 的时候将产生 ClassCastException。
实际上,编译器为了避免这种错误,根本就不允许把 ArrayList<Integer> 转型为 ArrayList<Number>。
ArrayList<Integer>和ArrayList<Number>两者完全没有继承关系。
ArrayList<Integer> 向上转型为 List<Integer>(T 不能变!),但不能把 ArrayList<Integer> 向上转型为 ArrayList<Number>(T 不能变成父类)。 使用 ArrayList 时,如果不定义泛型类型时,泛型类型实际上就是 Object:
1
2
3
4
5
6// 编译器警告:
List list = new ArrayList();
list.add("Hello");
list.add("World");
String first = (String) list.get(0);
String second = (String) list.get(1);
此时,只能把 <T> 当作 Object 使用,没有发挥泛型的优势。
当我们定义泛型类型 <String> 后,List<T> 的泛型接口变为强类型 List<String>:
1
2
3
4
5
6
7// 无编译器警告:
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("World");
// 无强制转型:
String first = list.get(0);
String second = list.get(1);
当我们定义泛型类型<Number>后,List<T>的泛型接口变为强类型List<Number>:
1
2
3
4
5List<Number> list = new ArrayList<Number>();
list.add(new Integer(123)); // add添加的是一个Number的实例,并且使用了向上转型
list.add(new Double(12.34));
Number first = list.get(0);
Number second = list.get(1);
编译器如果能自动推断出泛型类型,就可以省略后面的泛型类型。例如,对于下面的代码:
1
List<Number> list = new ArrayList<Number>();
编译器看到泛型类型List
1
2// 可以省略后面的Number,编译器可以自动推断泛型类型:
List<Number> list = new ArrayList<>();
除了 ArrayList<T> 使用了泛型,还可以在接口中使用泛型。例如,Arrays.sort(Object[]) 可以对任意数组进行排序,但待排序的元素必须实现 Comparable<T> 这个泛型接口:
1
2
3
4
5
6
7
8public interface Comparable<T> {
/**
* 返回负数: 当前实例比参数o小
* 返回0: 当前实例与参数o相等
* 返回正数: 当前实例比参数o大
*/
int compareTo(T o);
}
可以直接对String数组进行排序:
1
2
3
4
5
6
7
8
9import java.util.Arrays;
public class Main {
public static void main(String[] args) {
String[] ss = new String[] { "Orange", "Apple", "Pear" };
Arrays.sort(ss);
System.out.println(Arrays.toString(ss));
}
}
这是因为 String 本身已经实现了 Comparable<String> 接口。如果换成我们自定义的 Person 类型试试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import java.util.Arrays;
public class Main {
public static void main(String[] args) {
Person[] ps = new Person[] {
new Person("Bob", 61),
new Person("Alice", 88),
new Person("Lily", 75),
};
Arrays.sort(ps);
System.out.println(Arrays.toString(ps));
}
}
class Person {
String name;
int score;
Person(String name, int score) {
this.name = name;
this.score = score;
}
public String toString() {
return this.name + "," + this.score;
}
}
运行程序,我们会得到ClassCastException,即无法将Person转型为Comparable。我们修改代码,让Person实现Comparable<T>接口:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import java.util.Arrays;
public class Main {
public static void main(String[] args) {
Person[] ps = new Person[] {
new Person("Bob", 61),
new Person("Alice", 88),
new Person("Lily", 75),
};
Arrays.sort(ps);
System.out.println(Arrays.toString(ps));
}
}
class Person implements Comparable<Person> {
String name;
int score;
Person(String name, int score) {
this.name = name;
this.score = score;
}
public int compareTo(Person other) {
return this.name.compareTo(other.name);
}
public String toString() {
return this.name + "," + this.score;
}
}
运行上述代码,可以正确实现按name进行排序。
也可以修改比较逻辑,例如,按score从高到低排序。请自行修改测试。
<T>替换为需要的class类型,例如:ArrayList<String>,ArrayList<Number>等;List<String> list = new ArrayList<>();;<T>视为Object类型; 编写泛型类比普通类要复杂。通常来说,泛型类一般用在集合类中,例如ArrayList<T>,我们很少需要编写泛型类。
如果我们确实需要编写一个泛型类,那么,应该如何编写它?
可以按照以下步骤来编写一个泛型类。
首先,按照某种类型,例如:String,来编写类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Pair {
private String first;
private String last;
public Pair(String first, String last) {
this.first = first;
this.last = last;
}
public String getFirst() {
return first;
}
public String getLast() {
return last;
}
}
然后,标记所有的特定类型,这里是String:
最后,把特定类型String替换为T,并申明<T>:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
熟练后即可直接从T开始编写。
编写泛型类时,要特别注意,泛型类型 <T> 不能用于静态方法。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() { ... }
public T getLast() { ... }
// 对静态方法使用<T>:
public static Pair<T> create(T first, T last) {
return new Pair<T>(first, last);
}
}
上述代码会导致编译错误,我们无法在静态方法create()的方法参数和返回类型上使用泛型类型T。
有些同学在网上搜索发现,可以在static修饰符后面加一个<T>,编译就能通过:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() { ... }
public T getLast() { ... }
// 可以编译通过:
public static <T> Pair<T> create(T first, T last) {
return new Pair<T>(first, last);
}
}
但实际上,这个<T>和Pair<T>类型的<T>已经没有任何关系了。
对于静态方法,我们可以单独改写为“泛型”方法,只需要使用另一个类型即可。对于上面的create()静态方法,我们应该把它改为另一种泛型类型,例如,<K>:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() { ... }
public T getLast() { ... }
// 静态泛型方法应该使用其他类型区分:
public static <K> Pair<K> create(K first, K last) {
return new Pair<K>(first, last);
}
}
这样才能清楚地将静态方法的泛型类型和实例类型的泛型类型区分开。
泛型还可以定义多种类型。例如,我们希望Pair不总是存储两个类型一样的对象,就可以使用类型<T, K>:
1
2
3
4
5
6
7
8
9
10public class Pair<T, K> {
private T first;
private K last;
public Pair(T first, K last) {
this.first = first;
this.last = last;
}
public T getFirst() { ... }
public K getLast() { ... }
}
使用的时候,需要指出两种类型:
1
Pair<String, Integer> p = new Pair<>("test", 123);
Java标准库的Map<K, V>就是使用两种泛型类型的例子。它对Key使用一种类型,对Value使用另一种类型。
<T>;<T>,必须定义其他类型(例如<K>)来实现静态泛型方法;Map<K, V>。 泛型是一种类似”模板代码“的技术,不同语言的泛型实现方式不一定相同。
Java语言的泛型实现方式是擦拭法(Type Erasure)。
所谓擦拭法是指,虚拟机对泛型其实一无所知,所有的工作都是编译器做的。
例如,我们编写了一个泛型类Pair
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
而虚拟机根本不知道泛型。这是虚拟机执行的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Pair {
private Object first;
private Object last;
public Pair(Object first, Object last) {
this.first = first;
this.last = last;
}
public Object getFirst() {
return first;
}
public Object getLast() {
return last;
}
}
因此,Java使用擦拭法实现泛型,导致了:
<T>视为Object;<T>实现安全的强制转型。 使用泛型的时候,我们编写的代码也是编译器看到的代码:
1
2
3Pair<String> p = new Pair<>("Hello", "world");
String first = p.getFirst();
String last = p.getLast();
而虚拟机执行的代码并没有泛型:
1
2
3Pair p = new Pair("Hello", "world");
String first = (String) p.getFirst();
String last = (String) p.getLast();
所以,Java的泛型是由编译器在编译时实行的,编译器内部永远把所有类型T视为Object处理,但是,在需要转型的时候,编译器会根据T的类型自动为我们实行安全地强制转型。
了解了Java泛型的实现方式——擦拭法,我们就知道了Java泛型的局限:
局限一:<T>不能是基本类型,例如int,因为实际类型是Object,Object类型无法持有基本类型:
1
Pair<int> p = new Pair<>(1, 2); // compile error!
局限二:无法取得带泛型的Class。观察以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public class Main {
public static void main(String[] args) {
Pair<String> p1 = new Pair<>("Hello", "world");
Pair<Integer> p2 = new Pair<>(123, 456);
Class c1 = p1.getClass();
Class c2 = p2.getClass();
System.out.println(c1==c2); // true
System.out.println(c1==Pair.class); // true
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
因为 T 是 Object,我们对 Pair<String> 和 Pair<Integer> 类型获取 Class 时,获取到的是同一个 Class,也就是 Pair 类的 Class。
换句话说,所有泛型实例,无论 T 的类型是什么,getClass() 返回同一个 Class 实例,因为编译后它们全部都是 Pair<Object>。
局限三:无法判断带泛型的类型:
1
2
3
4Pair<Integer> p = new Pair<>(123, 456);
// Compile error:
if (p instanceof Pair<String>) {
}
原因和前面一样,并不存在Pair<String>.class,而是只有唯一的Pair.class。
局限四:不能实例化T类型:
1
2
3
4
5
6
7
8
9public class Pair<T> {
private T first;
private T last;
public Pair() {
// Compile error:
first = new T();
last = new T();
}
}
上述代码无法通过编译,因为构造方法的两行语句:
1
2first = new T();
last = new T();
擦拭后实际上变成了:
1
2first = new Object();
last = new Object();
这样一来,创建 new Pair<String>() 和创建 new Pair<Integer>() 就全部成了 Object,显然编译器要阻止这种类型不对的代码。
要实例化 T 类型,我们必须借助额外的 Class<T> 参数:
1
2
3
4
5
6
7
8public class Pair<T> {
private T first;
private T last;
public Pair(Class<T> clazz) {
first = clazz.newInstance();
last = clazz.newInstance();
}
}
上述代码借助Class
1
Pair<String> pair = new Pair<>(String.class);
因为传入了Class
有些时候,一个看似正确定义的方法会无法通过编译。例如:
1
2
3
4
5public class Pair<T> {
public boolean equals(T t) {
return this == t;
}
}
这是因为,定义的equals(T t)方法实际上会被擦拭成equals(Object t),而这个方法是继承自Object的,编译器会阻止一个实际上会变成覆写的泛型方法定义。
换个方法名,避开与Object.equals(Object)的冲突就可以成功编译:
1
2
3
4
5public class Pair<T> {
public boolean same(T t) {
return this == t;
}
}
一个类可以继承自一个泛型类。例如:父类的类型是Pair<Integer>,子类的类型是IntPair,可以这么继承:
1
2public class IntPair extends Pair<Integer> {
}
使用的时候,因为子类IntPair并没有泛型类型,所以,正常使用即可:
1
IntPair ip = new IntPair(1, 2);
前面讲了,我们无法获取 Pair<T> 的 T 类型,即给定一个变量 Pair<Integer> p,无法从 p 中获取到 Integer 类型。
但是,在父类是泛型类型的情况下,编译器就必须把类型 T(对 IntPair 来说,也就是 Integer 类型)保存到子类的 class 文件中,不然编译器就不知道 IntPair 只能存取 Integer 这种类型。
在继承了泛型类型的情况下,子类可以获取父类的泛型类型。例如:IntPair 可以获取到父类的泛型类型 Integer。获取父类的泛型类型代码比较复杂:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38import java.lang.reflect.ParameterizedType;
import java.lang.reflect.Type;
public class Main {
public static void main(String[] args) {
Class<IntPair> clazz = IntPair.class;
Type t = clazz.getGenericSuperclass();
if (t instanceof ParameterizedType) {
ParameterizedType pt = (ParameterizedType) t;
Type[] types = pt.getActualTypeArguments(); // 可能有多个泛型类型
Type firstType = types[0]; // 取第一个泛型类型
Class<?> typeClass = (Class<?>) firstType;
System.out.println(typeClass); // Integer
}
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
class IntPair extends Pair<Integer> {
public IntPair(Integer first, Integer last) {
super(first, last);
}
}
因为Java引入了泛型,所以,只用Class来标识类型已经不够了。实际上,Java的类型系统结构如下:
1
2
3
4
5
6
7
8
9
10 ┌────┐
│Type│
└────┘
▲
│
┌────────────┬────────┴─────────┬───────────────┐
│ │ │ │
┌─────┐┌─────────────────┐┌────────────────┐┌────────────┐
│Class││ParameterizedType││GenericArrayType││WildcardType│
└─────┘└─────────────────┘└────────────────┘└────────────┘
<T>:Pair<String>.class;x instanceof Pair<String>;new T()。public boolean equals(T obj);<T>。 我们前面已经讲到了泛型的继承关系:Pair<Integer> 不是 Pair<Number> 的子类。
假设我们定义了 Pair<T>:
1
public class Pair<T> { ... }
然后,我们又针对 Pair<Number> 类型写了一个静态方法,它接收的参数类型是 Pair<Number>:
1
2
3
4
5
6
7public class PairHelper {
static int add(Pair<Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
return first.intValue() + last.intValue();
}
}
上述代码是可以正常编译的。使用的时候,我们传入:
1
int sum = PairHelper.add(new Pair<Number>(1, 2));
注意:传入的类型是Pair<Number>,实际参数类型是(Integer, Integer)。
既然实际参数是Integer类型,试试传入Pair<Integer>:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
int n = add(p);
System.out.println(n);
}
static int add(Pair<Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
return first.intValue() + last.intValue();
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
直接运行,会得到一个编译错误:
1
incompatible types: Pair<Integer> cannot be converted to Pair<Number>
原因很明显,因为Pair<Integer>不是Pair<Number>的子类,因此,add(Pair<Number>)不接受参数类型Pair<Integer>。
但是从add()方法的代码可知,传入Pair<Integer>是完全符合内部代码的类型规范,因为语句:
1
2Number first = p.getFirst();
Number last = p.getLast();
实际类型是Integer,引用类型是Number,没有问题。问题在于方法参数类型定死了只能传入Pair<Number>。
有没有办法使得方法参数接受Pair<Integer>?办法是有的,这就是使用Pair<? extends Number>使得方法接收所有泛型类型为Number或Number子类的Pair类型。我们把代码改写如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
int n = add(p);
System.out.println(n);
}
static int add(Pair<? extends Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
return first.intValue() + last.intValue();
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
}
这样一来,给方法传入 Pair<Integer> 类型时,它符合参数 Pair<? extends Number> 类型。这种使用 <? extends Number > 的泛型定义称之为上界通配符(Upper Bounds Wildcards),即把泛型类型 T 的上界限定在 Number 了。
除了可以传入 Pair<Integer> 类型,我们还可以传入 Pair<Double> 类型,Pair<BigDecimal> 类型等等,因为 Double 和 BigDecimal 都是 Number 的子类。
如果我们考察对 Pair<? extends Number> 类型调用 getFirst() 方法,实际的方法签名变成了:
1
<? extends Number> getFirst();
即返回值是Number或Number的子类,因此,可以安全赋值给Number类型的变量:
1
Number x = p.getFirst();
然后,我们不可预测实际类型就是Integer,例如,下面的代码是无法通过编译的:
1
Integer x = p.getFirst();
这是因为实际的返回类型可能是Integer,也可能是Double或者其他类型,编译器只能确定类型一定是Number的子类(包括Number类型本身),但具体类型无法确定。
我们再来考察一下Pair<T>的set方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
int n = add(p);
System.out.println(n);
}
static int add(Pair<? extends Number> p) {
Number first = p.getFirst();
Number last = p.getLast();
p.setFirst(new Integer(first.intValue() + 100));
p.setLast(new Integer(last.intValue() + 100));
return p.getFirst().intValue() + p.getFirst().intValue();
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
public void setFirst(T first) {
this.first = first;
}
public void setLast(T last) {
this.last = last;
}
}
不出意外,我们会得到一个编译错误:
1
2
3incompatible types: Integer cannot be converted to CAP#1
where CAP#1 is a fresh type-variable:
CAP#1 extends Number from capture of ? extends Number
编译错误发生在p.setFirst()传入的参数是Integer类型。有些童鞋会问了,既然p的定义是Pair<? extends Number>,那么setFirst(? extends Number)为什么不能传入Integer?
原因还在于擦拭法。如果我们传入的p是Pair<Double>,显然它满足参数定义Pair<? extends Number>,然而,Pair<Double>的setFirst()显然无法接受Integer类型。
这就是<? extends Number>通配符的一个重要限制:方法参数签名setFirst(? extends Number)无法传递任何Number的子类型给setFirst(? extends Number)。
这里唯一的例外是可以给方法参数传入null:
1
2p.setFirst(null); // ok, 但是后面会抛出NullPointerException
p.getFirst().intValue(); // NullPointerException
如果我们考察Java标准库的java.util.List<T>接口,它实现的是一个类似“可变数组”的列表,主要功能包括:
1
2
3
4
5
6public interface List<T> {
int size(); // 获取个数
T get(int index); // 根据索引获取指定元素
void add(T t); // 添加一个新元素
void remove(T t); // 删除一个已有元素
}
现在,让我们定义一个方法来处理列表的每个元素:
1
2
3
4
5
6
7
8int sumOfList(List<? extends Integer> list) {
int sum = 0;
for (int i=0; i<list.size(); i++) {
Integer n = list.get(i);
sum = sum + n;
}
return sum;
}
为什么我们定义的方法参数类型是List<? extends Integer>而不是List<Integer>?从方法内部代码看,传入List<? extends Integer>或者List<Integer>是完全一样的,但是,注意到List<? extends Integer>的限制:
因此,方法参数类型List<? extends Integer>表明了该方法内部只会读取List的元素,不会修改List的元素(因为无法调用add(? extends Integer)、remove(? extends Integer)这些方法。换句话说,这是一个对参数List<? extends Integer>进行只读的方法(恶意调用set(null)除外)。
在定义泛型类型Pair
1
public class Pair<T extends Number> { ... }
现在,我们只能定义:
1
2
3Pair<Number> p1 = null;
Pair<Integer> p2 = new Pair<>(1, 2);
Pair<Double> p3 = null
因为Number、Integer和Double都符合<T extends Number>。
非Number类型将无法通过编译:
1
2Pair<String> p1 = null; // compile error!
Pair<Object> p2 = null; // compile error!
因为String、Object都不符合<T extends Number>,因为它们不是Number类型或Number的子类。
Number n = obj.getFirst();;obj.setFirst(Number n);。即一句话总结:使用extends通配符表示可以读,不能写。
我们前面已经讲到了泛型的继承关系:Pair<Integer>不是Pair<Number>的子类。
考察下面的set方法:
1
2
3
4void set(Pair<Integer> p, Integer first, Integer last) {
p.setFirst(first);
p.setLast(last);
}
传入 Pair<Integer> 是允许的,但是传入 Pair<Number> 是不允许的。
和 extends 通配符相反,这次,我们希望接受 Pair<Integer> 类型,以及 Pair<Number>、Pair<Object>,因为 Number 和 Object 是 Integer 的父类,setFirst(Number) 和 setFirst(Object) 实际上允许接受 Integer 类型。
我们使用super通配符来改写这个方法:
1
2
3
4void set(Pair<? super Integer> p, Integer first, Integer last) {
p.setFirst(first);
p.setLast(last);
}
注意到Pair<? super Integer>表示,方法参数接受所有泛型类型为Integer或Integer父类的Pair类型。
下面的代码可以被正常编译:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public class Main {
public static void main(String[] args) {
Pair<Number> p1 = new Pair<>(12.3, 4.56);
Pair<Integer> p2 = new Pair<>(123, 456);
setSame(p1, 100);
setSame(p2, 200);
System.out.println(p1.getFirst() + ", " + p1.getLast());
System.out.println(p2.getFirst() + ", " + p2.getLast());
}
static void setSame(Pair<? super Integer> p, Integer n) {
p.setFirst(n);
p.setLast(n);
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
public void setFirst(T first) {
this.first = first;
}
public void setLast(T last) {
this.last = last;
}
}
考察 Pair<? super Integer>的setFirst()方法,它的方法签名实际上是:
1
void setFirst(? super Integer);
因此,可以安全地传入Integer类型。
再考察Pair<? super Integer>的getFirst()方法,它的方法签名实际上是:
1
? super Integer getFirst();
这里注意到我们无法使用Integer类型来接收getFirst()的返回值,即下面的语句将无法通过编译:
1
Integer x = p.getFirst();
因为如果传入的实际类型是Pair<Number>,编译器无法将Number类型转型为Integer。
注意:虽然Number是一个抽象类,我们无法直接实例化它。但是,即便Number不是抽象类,这里仍然无法通过编译。此外,传入Pair<Object>类型时,编译器也无法将Object类型转型为Integer。
唯一可以接收getFirst()方法返回值的是Object类型:
1
Object obj = p.getFirst();
因此,使用<? super Integer>通配符表示:
唯一例外是可以获取Object的引用:Object o = p.getFirst()。
换句话说,使用<? super Integer>通配符作为方法参数,表示方法内部代码对于参数只能写,不能读。
我们再回顾一下extends通配符。作为方法参数,<? extends T>类型和<? super T>类型的区别在于:
<? extends T>允许调用读方法T get()获取T的引用,但不允许调用写方法set(T)传入T的引用(传入null除外);<? super T>允许调用写方法set(T)传入T的引用,但不允许调用读方法T get()获取T的引用(获取Object除外)。 一个是允许读不允许写,另一个是允许写不允许读。
先记住上面的结论,我们来看Java标准库的Collections类定义的copy()方法:
1
2
3
4
5
6
7
8
9public class Collections {
// 把src的每个元素复制到dest中:
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
for (int i=0; i<src.size(); i++) {
T t = src.get(i);
dest.add(t);
}
}
}
它的作用是把一个List的每个元素依次添加到另一个List中。它的第一个参数是List<? super T>,表示目标List,第二个参数List<? extends T>,表示要复制的List。我们可以简单地用for循环实现复制。在for循环中,我们可以看到,对于类型<? extends T>的变量src,我们可以安全地获取类型T的引用,而对于类型<? super T>的变量dest,我们可以安全地传入T的引用。
这个copy()方法的定义就完美地展示了extends和super的意图:
这是由编译器检查来实现的。如果在方法代码中意外修改了src,或者意外读取了dest,就会导致一个编译错误:
1
2
3
4
5
6
7
8public class Collections {
// 把src的每个元素复制到dest中:
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
...
T t = dest.get(0); // compile error!
src.add(t); // compile error!
}
}
这个copy()方法的另一个好处是可以安全地把一个List<Integer>添加到List<Number>,但是无法反过来添加:
1
2
3
4
5
6
7// copy List<Integer> to List<Number> ok:
List<Number> numList = ...;
List<Integer> intList = ...;
Collections.copy(numList, intList);
// ERROR: cannot copy List<Number> to List<Integer>:
Collections.copy(intList, numList);
而这些都是通过super和extends通配符,并由编译器强制检查来实现的。
何时使用extends,何时使用super?为了便于记忆,我们可以用PECS原则:Producer Extends Consumer Super。
即:如果需要返回T,它是生产者(Producer),要使用extends通配符;如果需要写入T,它是消费者(Consumer),要使用super通配符。
还是以Collections的copy()方法为例:
1
2
3
4
5
6
7
8public class Collections {
public static <T> void copy(List<? super T> dest, List<? extends T> src) {
for (int i=0; i<src.size(); i++) {
T t = src.get(i); // src是producer
dest.add(t); // dest是consumer
}
}
}
需要返回T的src是生产者,因此声明为List<? extends T>,需要写入T的dest是消费者,因此声明为List<? super T>。
我们已经讨论了<? extends T>和<? super T>作为方法参数的作用。实际上,Java的泛型还允许使用无限定通配符(Unbounded Wildcard Type),即只定义一个?:
1
2
3void sample(Pair<?> p) {
}
因为<?>通配符既没有extends,也没有super,因此:
换句话说,既不能读,也不能写,那只能做一些null判断:
1
2
3static boolean isNull(Pair<?> p) {
return p.getFirst() == null || p.getLast() == null;
}
大多数情况下,可以引入泛型参数<T>消除<?>通配符:
1
2
3static <T> boolean isNull(Pair<T> p) {
return p.getFirst() == null || p.getLast() == null;
}
<?>通配符有一个独特的特点,就是:Pair<?>是所有Pair<T>的超类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public class Main {
public static void main(String[] args) {
Pair<Integer> p = new Pair<>(123, 456);
Pair<?> p2 = p; // 安全地向上转型
System.out.println(p2.getFirst() + ", " + p2.getLast());
}
}
class Pair<T> {
private T first;
private T last;
public Pair(T first, T last) {
this.first = first;
this.last = last;
}
public T getFirst() {
return first;
}
public T getLast() {
return last;
}
public void setFirst(T first) {
this.first = first;
}
public void setLast(T last) {
this.last = last;
}
}
上述代码是可以正常编译运行的,因为Pair<Integer>是Pair<?>的子类,可以安全地向上转型。
即使用super通配符表示只能写不能读。
<T>替换,同时它是所有<T>类型的超类。 在语言层面上提供一个异常处理机制。
Java 内置了一套异常处理机制,总是使用异常来表示错误。
异常是一种 class,因此它本身带有类型信息。异常可以在任何地方抛出,但只需要在上层捕获,这样就和方法调用分离了:
1 | try { |
Note: 编译器对 RuntimeException 及其子类不做强制捕获要求,不是指应用程序本身不应该捕获并处理 RuntimeException。是否需要捕获,具体问题具体分析。
捕获异常使用 try…catch 语句,把可能发生异常的代码放到 try {…} 中,然后使用 catch 捕获对应的 Exception 及其子类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Main {
public static void main(String[] args) {
byte[] bs = toGBK("中文");
System.out.println(Arrays.toString(bs));
}
static byte[] toGBK(String s) {
try {
// 用指定编码转换 String 为 byte[]:
return s.getBytes("GBK");
} catch (UnsupportedEncodingException e) {
// 如果系统不支持 GBK 编码,会捕获到 UnsupportedEncodingException:
System.out.println(e); // 打印异常信息
return s.getBytes(); // 尝试使用用默认编码
}
}
}
如果我们不捕获 UnsupportedEncodingException,会出现编译失败的问题
编译器会报错,错误信息类似:unreported exception UnsupportedEncodingException; must be caught or declared to be thrown,并且准确地指出需要捕获的语句是 return s.getBytes(“GBK”);。意思是说,像 UnsupportedEncodingException 这样的 Checked Exception,必须被捕获。
这是因为 String.getBytes(String) 方法定义是:
1
2
3public byte[] getBytes(String charsetName) throws UnsupportedEncodingException {
...
}
在方法定义的时候,使用 throws Xxx 表示该方法可能抛出的异常类型。调用方在调用的时候,必须强制捕获这些异常,否则编译器会报错。
在 toGBK() 方法中,因为调用了 String.getBytes(String) 方法,就必须捕获 UnsupportedEncodingException。我们也可以不捕获它,而是在方法定义处用 throws 表示 toGBK() 方法可能会抛出 UnsupportedEncodingException,就可以让 toGBK() 方法通过编译器检查:
1
2
3
4
5
6
7
8
9
10public class Main {
public static void main(String[] args) {
byte[] bs = toGBK("中文");
System.out.println(Arrays.toString(bs));
}
static byte[] toGBK(String s) throws UnsupportedEncodingException {
return s.getBytes("GBK");
}
}
上述代码仍然会得到编译错误,但这一次,编译器提示的不是调用 return s.getBytes(“GBK”); 的问题,而是 byte[] bs = toGBK(“中文”);。因为在 main() 方法中,调用 toGBK(),没有捕获它声明的可能抛出的 UnsupportedEncodingException。
修复方法是在 main() 方法中捕获异常并处理:
1
2
3
4
5
6
7
8
9
10
11public class Main {
public static void main(String[] args) throws Exception {
byte[] bs = toGBK("中文");
System.out.println(Arrays.toString(bs));
}
static byte[] toGBK(String s) throws UnsupportedEncodingException {
// 用指定编码转换 String 为 byte[]:
return s.getBytes("GBK");
}
}
因为 main() 方法声明了可能抛出 Exception,也就声明了可能抛出所有的 Exception,因此在内部就无需捕获了。代价就是一旦发生异常,程序会立刻退出。
还有一些童鞋喜欢在 toGBK() 内部 “消化” 异常:
1
2
3
4
5
6
7static byte[] toGBK(String s) {
try {
return s.getBytes("GBK");
} catch (UnsupportedEncodingException e) {
// 什么也不干
}
return null;
这种捕获后不处理的方式是非常不好的,即使真的什么也做不了,也要先把异常记录下来:
1
2
3
4
5
6
7
8static byte[] toGBK(String s) {
try {
return s.getBytes("GBK");
} catch (UnsupportedEncodingException e) {
// 先记下来再说:
e.printStackTrace();
}
return null;
所有异常都可以调用 printStackTrace() 方法打印异常栈,这是一个简单有用的快速打印异常的方法。
在 Java 中,凡是可能抛出异常的语句,都可以用 try … catch 捕获。把可能发生异常的语句放在 try {…} 中,然后使用 catch 捕获对应的 Exception 及其子类。
可以使用多个 catch 语句,每个 catch 分别捕获对应的 Exception 及其子类。JVM 在捕获到异常后,会从上到下匹配 catch 语句,匹配到某个 catch 后,执行 catch 代码块,然后不再继续匹配。
简单地说就是:多个 catch 语句只有一个能被执行。例如:
1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println(e);
} catch (NumberFormatException e) {
System.out.println(e);
}
}
存在多个 catch 的时候,catch 的顺序非常重要:子类必须写在前面。例如:
1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException e) {
System.out.println("IO error");
} catch (UnsupportedEncodingException e) { // 永远捕获不到
System.out.println("Bad encoding");
}
}
对于上面的代码,UnsupportedEncodingException 异常是永远捕获不到的,因为它是 IOException 的子类。当抛出 UnsupportedEncodingException 异常时,会被 catch (IOException e) { … } 捕获并执行。
因此,正确的写法是把子类放到前面:
1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
} catch (IOException e) {
System.out.println("IO error");
}
}
无论是否有异常发生,如果我们都希望执行一些语句,例如清理工作,怎么写?
可以把执行语句写若干遍:正常执行的放到 try 中,每个 catch 再写一遍。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public static void main(String[] args) {
try {
process1();
process2();
process3();
System.out.println("END");
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
System.out.println("END");
} catch (IOException e) {
System.out.println("IO error");
System.out.println("END");
}
}
上述代码无论是否发生异常,都会执行 System.out.println(“END”); 这条语句。
Java 的 try … catch 机制还提供了 finally 语句,finally 语句块保证有无错误都会执行。上述代码可以改写如下:
1
2
3
4
5
6
7
8
9
10
11
12
13public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (UnsupportedEncodingException e) {
System.out.println("Bad encoding");
} catch (IOException e) {
System.out.println("IO error");
} finally {
System.out.println("END");
}
}
注意 finally 有几个特点:
如果没有发生异常,就正常执行 try {…} 语句块,然后执行 finally。如果发生了异常,就中断执行 try { … } 语句块,然后跳转执行匹配的 catch 语句块,最后执行 finally。
可见,finally 是用来保证一些代码必须执行的。
某些情况下,可以没有 catch,只使用 try … finally 结构。例如:
1
2
3
4
5
6
7void process(String file) throws IOException {
try {
...
} finally {
System.out.println("END");
}
}
因为方法声明了可能抛出的异常,所以可以不写 catch。
写上 try-finally 即便抛出异常,也会执行 finally 块的语句,而 try 后面的语句则不会执行了
有 try-catch 和 方法抛出异常的区别:try-catch 捕获异常后会继续执行后面的语句,相当于是个桥梁路还是通着的,如果是方法抛出,那么则不会执行后面的语句了,相当于桥断了。
1 | public static void main(String[] args) { |
因为处理 IOException 和 NumberFormatException 的代码是相同的,所以我们可以把它两用 | 合并到一起:
1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args) {
try {
process1();
process2();
process3();
} catch (IOException | NumberFormatException e) { // IOException 或 NumberFormatException
System.out.println("Bad input");
} catch (Exception e) {
System.out.println("Unknown error");
}
}
当某个方法抛出了异常时,如果当前方法没有捕获异常,异常就会被抛到上层调用方法,直到遇到某个 try … catch 被捕获为止:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
process2();
}
static void process2() {
Integer.parseInt(null); // 会抛出 NumberFormatException
}
}
通过 printStackTrace() 可以打印出方法的调用栈,类似:
1
2
3
4
5
6java.lang.NumberFormatException: null
at java.lang.Integer.parseInt(Integer.java:542)
at java.lang.Integer.parseInt(Integer.java:615)
at class3.module3.Test1.process2(Test1.java:23)
at class3.module3.Test1.process1(Test1.java:19)
at class3.module3.Test1.main(Test1.java:12)
printStackTrace() 对于调试错误非常有用,上述信息表示:NumberFormatException 是在 java.lang.Integer.parseInt 方法中被抛出的,从下往上看,调用层次依次是:
查看 Integer.java 源码可知,抛出异常的方法代码如下:
1
2
3
4
5
6public static int parseInt(String s, int radix) throws NumberFormatException {
if (s == null) {
throw new NumberFormatException("null");
}
...
}
并且,每层调用均给出了源代码的行号,可直接定位。
当发生错误时,例如,用户输入了非法的字符,我们就可以抛出异常。
如何抛出异常?参考 Integer.parseInt() 方法,抛出异常分两步:
下面是一个例子:
1
2
3
4
5
6void process2(String s) {
if (s==null) {
NullPointerException e = new NullPointerException();
throw e;
}
}
实际上,绝大部分抛出异常的代码都会合并写成一行:
1
2
3
4
5void process2(String s) {
if (s==null) {
throw new NullPointerException();
}
}
如果一个方法捕获了某个异常后,又在 catch 子句中抛出新的异常,就相当于把抛出的异常类型 “转换” 了:
1
2
3
4
5
6
7
8
9
10
11
12
13void process1(String s) {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException();
}
}
void process2(String s) {
if (s==null) {
throw new NullPointerException();
}
}
当 process2() 抛出 NullPointerException 后,被 process1() 捕获,然后抛出 IllegalArgumentException()。
如果在 main() 中捕获 IllegalArgumentException,我们看看打印的异常栈:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException();
}
}
static void process2() {
throw new NullPointerException();
}
}
打印出的异常栈类似:
1
2
3java.lang.IllegalArgumentException
at Main.process1(Main.java:15)
at Main.main(Main.java:5)
这说明新的异常丢失了原始异常信息,我们已经看不到原始异常 NullPointerException 的信息了。
为了能追踪到完整的异常栈,在构造异常的时候,把原始的 Exception 实例传进去,新的 Exception 就可以持有原始 Exception 信息。对上述代码改进如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class Main {
public static void main(String[] args) {
try {
process1();
} catch (Exception e) {
e.printStackTrace();
}
}
static void process1() {
try {
process2();
} catch (NullPointerException e) {
throw new IllegalArgumentException(e);
}
}
static void process2() {
throw new NullPointerException();
}
}
运行上述代码,打印出的异常栈类似:
1
2
3
4
5
6java.lang.IllegalArgumentException: java.lang.NullPointerException
at Main.process1(Main.java:15)
at Main.main(Main.java:5)
Caused by: java.lang.NullPointerException
at Main.process2(Main.java:20)
at Main.process1(Main.java:13)
注意到 Caused by: Xxx,说明捕获的 IllegalArgumentException 并不是造成问题的根源,根源在于 NullPointerException,是在 Main.process2() 方法抛出的。
在代码中获取原始异常可以使用 Throwable.getCause() 方法。如果返回 null,说明已经是 “根异常” 了。
有了完整的异常栈的信息,我们才能快速定位并修复代码的问题。
捕获到异常并再次抛出时,一定要留住原始异常,否则很难定位第一案发现场!
如果我们在 try 或者 catch 语句块中抛出异常,finally 语句是否会执行?例如:
2
3
4
5
6
7
8
9
10
11
12
public static void main(String[] args) {
try {
Integer.parseInt("abc");
} catch (Exception e) {
System.out.println("catched");
throw new RuntimeException(e);
} finally {
System.out.println("finally");
}
}
}
上述代码执行结果如下:
2
3
4
5
6
finally
Exception in thread "main" java.lang.RuntimeException: java.lang.NumberFormatException: For input string: "abc"
at Main.main(Main.java:8)
Caused by: java.lang.NumberFormatException: For input string: "abc"
at ...
第一行打印了 catched,说明进入了 catch 语句块。第二行打印了 finally,说明执行了 finally 语句块。
因此,在 catch 中抛出异常,不会影响 finally 的执行。JVM 会先执行 finally,然后抛出异常。
如果在执行 finally 语句时抛出异常,那么,catch 语句的异常还能否继续抛出?例如:
1
2
3
4
5
6
7
8
9
10
11
12
13public class Main {
public static void main(String[] args) {
try {
Integer.parseInt("abc");
} catch (Exception e) {
System.out.println("catched");
throw new RuntimeException(e);
} finally {
System.out.println("finally");
throw new IllegalArgumentException();
}
}
}
执行上述代码,发现异常信息如下:
1
2
3
4catched
finally
Exception in thread "main" java.lang.IllegalArgumentException
at Main.main(Main.java:11)
这说明 finally 抛出异常后,原来在 catch 中准备抛出的异常就 “消失” 了,因为只能抛出一个异常。没有被抛出的异常称为 “被屏蔽” 的异常(Suppressed Exception)。
在极少数的情况下,我们需要获知所有的异常。如何保存所有的异常信息?方法是先用 origin 变量保存原始异常,然后调用 Throwable.addSuppressed(),把原始异常添加进来,最后在 finally 抛出:
1
2
3
4catched
finally
Exception in thread "main" java.lang.IllegalArgumentException
at Main.main(Main.java:11)
这说明 finally 抛出异常后,原来在 catch 中准备抛出的异常就 “消失” 了,因为只能抛出一个异常。没有被抛出的异常称为 “被屏蔽” 的异常(Suppressed Exception)。
在极少数的情况下,我们需要获知所有的异常。如何保存所有的异常信息?方法是先用 origin 变量保存原始异常,然后调用 Throwable.addSuppressed(),把原始异常添加进来,最后在 finally 抛出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Main {
public static void main(String[] args) throws Exception {
Exception origin = null;
try {
System.out.println(Integer.parseInt("abc"));
} catch (Exception e) {
origin = e;
throw e;
} finally {
Exception e = new IllegalArgumentException();
if (origin != null) {
e.addSuppressed(origin);
}
throw e;
}
}
}
当 catch 和 finally 都抛出了异常时,虽然 catch 的异常被屏蔽了,但是,finally 抛出的异常仍然包含了它:
1
2
3
4
5
6
7Exception in thread "main" java.lang.IllegalArgumentException
at Main.main(Main.java:11)
Suppressed: java.lang.NumberFormatException: For input string: "abc"
at java.base/java.lang.NumberFormatException.forInputString(NumberFormatException.java:65)
at java.base/java.lang.Integer.parseInt(Integer.java:652)
at java.base/java.lang.Integer.parseInt(Integer.java:770)
at Main.main(Main.java:6)
通过 Throwable.getSuppressed() 可以获取所有的 Suppressed Exception。
绝大多数情况下,在 finally 中不要抛出异常。因此,我们通常不需要关心 Suppressed Exception。
Java 标准库定义的常用异常包括:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29Exception
│
├─ RuntimeException
│ │
│ ├─ NullPointerException
│ │
│ ├─ IndexOutOfBoundsException
│ │
│ ├─ SecurityException
│ │
│ └─ IllegalArgumentException
│ │
│ └─ NumberFormatException
│
├─ IOException
│ │
│ ├─ UnsupportedCharsetException
│ │
│ ├─ FileNotFoundException
│ │
│ └─ SocketException
│
├─ ParseException
│
├─ GeneralSecurityException
│
├─ SQLException
│
└─ TimeoutException
当我们在代码中需要抛出异常时,尽量使用 JDK 已定义的异常类型。例如,参数检查不合法,应该抛出 IllegalArgumentException:
1
2
3
4
5static void process1(int age) {
if (age <= 0) {
throw new IllegalArgumentException();
}
}
在一个大型项目中,可以自定义新的异常类型,但是,保持一个合理的异常继承体系是非常重要的。
一个常见的做法是自定义一个 BaseException 作为 “根异常”,然后,派生出各种业务类型的异常。
BaseException 需要从一个适合的 Exception 派生,通常建议从 RuntimeException 派生:
1
2
3public class BaseException extends RuntimeException {
}
其他业务类型的异常就可以从 BaseException 派生:
1
2
3
4
5
6
7public class UserNotFoundException extends BaseException {
}
public class LoginFailedException extends BaseException {
}
...
自定义的 BaseException 应该提供多个构造方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class BaseException extends RuntimeException {
public BaseException() {
super();
}
public BaseException(String message, Throwable cause) {
super(message, cause);
}
public BaseException(String message) {
super(message);
}
public BaseException(Throwable cause) {
super(cause);
}
}
上述构造方法实际上都是原样照抄 RuntimeException。这样,抛出异常的时候,就可以选择合适的构造方法。通过 IDE 可以根据父类快速生成子类的构造方法。
NullPointerException 即空指针异常,俗称 NPE。如果一个对象为 null,调用其方法或访问其字段就会产生 NullPointerException,这个异常通常是由 JVM 抛出的,例如:
1
2
3
4
5public class Main {public static void main(String[] args) {
String s = null;
System.out.println(s.toLowerCase());
}
}
指针这个概念实际上源自 C 语言,Java 语言中并无指针。我们定义的变量实际上是引用,Null Pointer 更确切地说是 Null Reference,不过两者区别不大。
如果遇到 NullPointerException,我们应该如何处理?首先,必须明确,NullPointerException 是一种代码逻辑错误,遇到 NullPointerException,遵循原则是早暴露,早修复,严禁使用 catch 来隐藏这种编码错误:
1
2
3
4
5
6// 错误示例: 捕获 NullPointerException
try {
transferMoney(from, to, amount);
} catch (NullPointerException e) {
}
好的编码习惯可以极大地降低 NullPointerException 的产生,例如:
成员变量在定义时初始化:
1
2
3public class Person {
private String name = "";
}
使用空字符串 "" 而不是默认的 null 可避免很多 NullPointerException,编写业务逻辑时,用空字符串 "" 表示未填写比 null 安全得多。
返回空字符串 ""、空数组而不是 null:
1
2
3
4
5
6
7public String[] readLinesFromFile(String file) {
if (getFileSize(file) == 0) {
// 返回空数组而不是null:
return new String[0];
}
...
}
这样可以使得调用方无需检查结果是否为 null。
如果调用方一定要根据 null 判断,比如返回 null 表示文件不存在,那么考虑返回 Optional<T>:
1
2
3
4
5
6public Optional<String> readFromFile(String file) {
if (!fileExist(file)) {
return Optional.empty();
}
...
}
这样调用方必须通过Optional.isPresent()判断是否有结果。
如果产生了NullPointerException,例如,调用a.b.c.x()时产生了NullPointerException,原因可能是:
确定到底是哪个对象是null以前只能打印这样的日志:
System.out.println(a);
System.out.println(a.b);
System.out.println(a.b.c);
可以在 NullPointerException 的详细信息中看到类似 ... because "<local1>.address.city" is null,意思是 city 字段为 null,这样我们就能快速定位问题所在。
这种增强的 NullPointerException 详细信息是 Java 14 新增的功能,但默认是关闭的,我们可以给 JVM 添加一个 - XX:+ShowCodeDetailsInExceptionMessages 参数启用它:
1
java -XX:+ShowCodeDetailsInExceptionMessages Main.java
断言(Assertion)是一种调试程序的方式。在 Java 中,使用 assert 关键字来实现断言。
我们先看一个例子:
1
2
3
4
5public static void main(String[] args) {
double x = Math.abs(-123.45);
assert x >= 0;
System.out.println(x);
}
语句 assert x >= 0; 即为断言,断言条件 x >= 0 预期为 true。如果计算结果为 false,则断言失败,抛出 AssertionError。
使用 assert 语句时,还可以添加一个可选的断言消息:
1
assert x >= 0 : "x must >= 0";
这样,断言失败的时候,AssertionError 会带上消息 x must >= 0,更加便于调试。
Java 断言的特点是:断言失败时会抛出 AssertionError,导致程序结束退出。因此,断言不能用于可恢复的程序错误,只应该用于开发和测试阶段。
对于可恢复的程序错误,不应该使用断言。例如:
1
2
3void sort(int[] arr) {
assert arr != null;
}
应该抛出异常并在上层捕获:
1
2
3
4
5void sort(int[] arr) {
if (x == null) {
throw new IllegalArgumentException("array cannot be null");
}
}
当我们在程序中使用 assert 时,例如,一个简单的断言:
1
2
3
4
5
6
7public class Main {
public static void main(String[] args) {
int x = -1;
assert x > 0;
System.out.println(x);
}
}
断言 x 必须大于 0,实际上 x 为 - 1,断言肯定失败。执行上述代码,发现程序并未抛出 AssertionError,而是正常打印了 x 的值。
这是怎么肥四?为什么 assert 语句不起作用?
这是因为 JVM 默认关闭断言指令,即遇到 assert 语句就自动忽略了,不执行。
要执行 assert 语句,必须给 Java 虚拟机传递 -enableassertions(可简写为 -ea)参数启用断言。所以,上述程序必须在命令行下运行才有效果:
1
2
3$ java -ea Main.java
Exception in thread "main" java.lang.AssertionError
at Main.main(Main.java:5)
还可以有选择地对特定地类启用断言,命令行参数是:-ea:com.itranswarp.sample.Main,表示只对 com.itranswarp.sample.Main 这个类启用断言。
或者对特定地包启用断言,命令行参数是:-ea:com.itranswarp.sample...(注意结尾有 3 个.),表示对 com.itranswarp.sample 这个包启动断言。
实际开发中,很少使用断言。更好的方法是编写单元测试,后续我们会讲解 JUnit 的使用。
在编写程序的过程中,发现程序运行结果与预期不符,怎么办?当然是用 System.out.println() 打印出执行过程中的某些变量,观察每一步的结果与代码逻辑是否符合,然后有针对性地修改代码。
代码改好了怎么办?当然是删除没有用的 System.out.println() 语句了。
如果改代码又改出问题怎么办?再加上 System.out.println()。
反复这么搞几次,很快大家就发现使用 System.out.println() 非常麻烦。
怎么办?
解决方法是使用日志。
那什么是日志?日志就是 Logging,它的目的是为了取代 System.out.println()。
输出日志,而不是用 System.out.println(),有以下几个好处:
因为Java标准库内置了日志包java.util.logging,我们可以直接用。先看一个简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12import java.util.logging.Level;
import java.util.logging.Logger;
public class Hello {
public static void main(String[] args) {
Logger logger = Logger.getGlobal();
logger.info("start process...");
logger.warning("memory is running out...");
logger.fine("ignored.");
logger.severe("process will be terminated...");
}
}
输出
1
2
3
4
5
6Jan 15, 2021 5:57:27 AM Hello main
INFO: start process...
Jan 15, 2021 5:57:27 AM Hello main
WARNING: memory is running out...
Jan 15, 2021 5:57:27 AM Hello main
SEVERE: process will be terminated...
对比可见,使用日志最大的好处是,它自动打印了时间、调用类、调用方法等很多有用的信息。
再仔细观察发现,4 条日志,只打印了 3 条,logger.fine() 没有打印。这是因为,日志的输出可以设定级别。JDK 的 Logging 定义了 7 个日志级别,从严重到普通:
因为默认级别是 INFO,因此,INFO 级别以下的日志,不会被打印出来。使用日志级别的好处在于,调整级别,就可以屏蔽掉很多调试相关的日志输出。
使用 Java 标准库内置的 Logging 有以下局限:
Logging 系统在 JVM 启动时读取配置文件并完成初始化,一旦开始运行 main() 方法,就无法修改配置;
配置不太方便,需要在 JVM 启动时传递参数 -Djava.util.logging.config.file=<config-file-name>。
因此,Java 标准库内置的 Logging 使用并不是非常广泛。更方便的日志系统我们稍后介绍。
和Java标准库提供的日志不同,Commons Logging是一个第三方日志库,它是由Apache创建的日志模块。
Commons Logging的特色是,它可以挂接不同的日志系统,并通过配置文件指定挂接的日志系统。默认情况下,Commons Loggin自动搜索并使用Log4j(Log4j是另一个流行的日志系统),如果没有找到Log4j,再使用JDK Logging。
使用Commons Logging只需要和两个类打交道,并且只有两步:
第一步,通过LogFactory获取Log类的实例; 第二步,使用Log实例的方法打日志。
示例代码如下:
1
2
3
4
5
6
7
8
9
10import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
public class Main {
public static void main(String[] args) {
Log log = LogFactory.getLog(Main.class);
log.info("start...");
log.warn("end.");
}
}
运行上述代码,肯定会得到编译错误,类似error: package org.apache.commons.logging does not exist(找不到org.apache.commons.logging这个包)。因为Commons Logging是一个第三方提供的库,所以,必须先把它下载下来。下载后,解压,找到commons-logging-1.2.jar这个文件,再把Java源码Main.java放到一个目录下,例如work目录:
1
2
3
4
5work
│
├─ commons-logging-1.2.jar
│
└─ Main.java
然后用javac编译Main.java,编译的时候要指定classpath,不然编译器找不到我们引用的org.apache.commons.logging包。编译命令如下:
1
javac -cp commons-logging-1.2.jar Main.java
如果编译成功,那么当前目录下就会多出一个Main.class文件:
1
2
3
4
5
6
7work
│
├─ commons-logging-1.2.jar
│
├─ Main.java
│
└─ Main.class
现在可以执行这个Main.class,使用java命令,也必须指定classpath,命令如下:
1
java -cp .;commons-logging-1.2.jar Main
注意到传入的classpath有两部分:一个是.,一个是commons-logging-1.2.jar,用;分割。.表示当前目录,如果没有这个.,JVM不会在当前目录搜索Main.class,就会报错。
如果在Linux或macOS下运行,注意classpath的分隔符不是;,而是::
运行结果如下:
1
2
3
4Mar 02, 2019 7:15:31 PM Main main
INFO: start...
Mar 02, 2019 7:15:31 PM Main main
WARNING: end.
Commons Logging定义了6个日志级别:
1 | // 在静态方法中引用Log: |
1 | // 在实例方法中引用Log: |
LogFactory.getLog(getClass()),虽然也可以用 LogFactory.getLog(Person.class),但是前一种方式有个非常大的好处,就是子类可以直接使用该 log 实例。例如: 1 | // 在子类中使用父类实例化的log: |
LogFactory.getLog(Student.class),但却是从父类继承而来,并且无需改动代码。info(String, Throwable),这使得记录异常更加简单: 1 | try { |
前面介绍了Commons Logging,可以作为“日志接口”来使用。而真正的“日志实现”可以使用Log4j。
Log4j是一种非常流行的日志框架,最新版本是2.x。
Log4j是一个组件化设计的日志系统,它的架构大致如下:
1
2
3
4
5
6
7
8
9
10
11
12
13log.info("User signed in.");
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
├──>│ Appender │───>│ Filter │───>│ Layout │───>│ Console │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
├──>│ Appender │───>│ Filter │───>│ Layout │───>│ File │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘
│
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
└──>│ Appender │───>│ Filter │───>│ Layout │───>│ Socket │
└──────────┘ └──────────┘ └──────────┘ └──────────┘
当我们使用Log4j输出一条日志时,Log4j自动通过不同的Appender把同一条日志输出到不同的目的地。例如:
在输出日志的过程中,通过Filter来过滤哪些log需要被输出,哪些log不需要被输出。例如,仅输出ERROR级别的日志。
最后,通过Layout来格式化日志信息,例如,自动添加日期、时间、方法名称等信息。
上述结构虽然复杂,但我们在实际使用的时候,并不需要关心Log4j的API,而是通过配置文件来配置它。
以XML配置为例,使用Log4j的时候,我们把一个log4j2.xml的文件放到classpath下就可以让Log4j读取配置文件并按照我们的配置来输出日志。下面是一个配置文件的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
<Configuration>
<Properties>
<!-- 定义日志格式 -->
<Property name="log.pattern">%d{MM-dd HH:mm:ss.SSS} [%t] %-5level %logger{36}%n%msg%n%n</Property>
<!-- 定义文件名变量 -->
<Property name="file.err.filename">log/err.log</Property>
<Property name="file.err.pattern">log/err.%i.log.gz</Property>
</Properties>
<!-- 定义Appender,即目的地 -->
<Appenders>
<!-- 定义输出到屏幕 -->
<Console name="console" target="SYSTEM_OUT">
<!-- 日志格式引用上面定义的log.pattern -->
<PatternLayout pattern="${log.pattern}" />
</Console>
<!-- 定义输出到文件,文件名引用上面定义的file.err.filename -->
<RollingFile name="err" bufferedIO="true" fileName="${file.err.filename}" filePattern="${file.err.pattern}">
<PatternLayout pattern="${log.pattern}" />
<Policies>
<!-- 根据文件大小自动切割日志 -->
<SizeBasedTriggeringPolicy size="1 MB" />
</Policies>
<!-- 保留最近10份 -->
<DefaultRolloverStrategy max="10" />
</RollingFile>
</Appenders>
<Loggers>
<Root level="info">
<!-- 对info级别的日志,输出到console -->
<AppenderRef ref="console" level="info" />
<!-- 对error级别的日志,输出到err,即上面定义的RollingFile -->
<AppenderRef ref="err" level="error" />
</Root>
</Loggers>
</Configuration>
虽然配置Log4j比较繁琐,但一旦配置完成,使用起来就非常方便。对上面的配置文件,凡是INFO级别的日志,会自动输出到屏幕,而ERROR级别的日志,不但会输出到屏幕,还会同时输出到文件。并且,一旦日志文件达到指定大小(1MB),Log4j就会自动切割新的日志文件,并最多保留10份。
有了配置文件还不够,因为Log4j也是一个第三方库,我们需要从这里下载Log4j,解压后,把以下3个jar包放到classpath中:
因为Commons Logging会自动发现并使用Log4j,所以,把上一节下载的commons-logging-1.2.jar也放到classpath中。
要打印日志,只需要按Commons Logging的写法写,不需要改动任何代码,就可以得到Log4j的日志输出,类似:
1
203-03 12:09:45.880 [main] INFO com.itranswarp.learnjava.Main
Start process...
在开发阶段,始终使用Commons Logging接口来写入日志,并且开发阶段无需引入Log4j。如果需要把日志写入文件, 只需要把正确的配置文件和Log4j相关的jar包放入classpath,就可以自动把日志切换成使用Log4j写入,无需修改任何代码。
通过Commons Logging实现日志,不需要修改代码即可使用Log4j;
使用Log4j只需要把log4j2.xml和相关jar放入classpath;
如果要更换Log4j,只需要移除log4j2.xml和相关jar;
只有扩展Log4j时,才需要引用Log4j的接口(例如,将日志加密写入数据库的功能,需要自己开发)。
1 | public synchronized void method(int args) { |
synchronized方法控制对“对象”的访问,每个对象对应一把锁,每个synchronized方法都必须获得该方法的对象的多才能执行,否则线程会阻塞,方法一旦执行,就独占该锁,知道该方法返回才释放锁,后面被阻塞的线程才能获得这个锁,继续执行
1 | synchronized (Obj) { |
Obj 称之为 同步监视器:
this,就是这个对象本身,或者是 class同步监视器的执行过程:
总结:锁的对象就是变化的量:需要增删改的对象
简单定义:多个线程互相抱着对方需要的资源才能运行,然后形成僵持
多个线程各自占有一些共享资源,并且互相等待其他线程占有的资源才能运行,而导致两个或多个线程都在等待对方释放资源,都停止执行的情形。某一个同步块同时拥有“两个以上对象的锁”时,就可能会发生“死锁”问题。
1 | public class Main { |
1 | public class Main { |
1 | Thread t = new Thread(() -> { |
1 | new Thread(()-> { |
要想给每个实例不一样的参数:用构造函数
1 | public class Main { |
在了解 Maven 之前,我们先来看看一个 Java 项目需要的东西。首先,我们需要确定引入哪些依赖包。例如,如果我们需要用到 commons logging,我们就必须把 commons logging 的 jar 包放入 classpath。如果我们还需要 log4j,就需要把 log4j 相关的 jar 包都放到 classpath 中。这些就是依赖包的管理。
其次,我们要确定项目的目录结构。例如,src 目录存放 Java源码,resources 目录存放 配置文件,bin 目录存放编译生成的 .class 文件。
此外,我们还需要配置环境,例如 JDK 的版本,编译打包的流程,当前代码的版本号。
最后,除了使用 Eclipse 这样的 IDE 进行编译外,我们还必须能通过命令行工具进行编译,才能够让项目在一个独立的服务器上编译、测试、部署。
这些工作难度不大,但是非常琐碎且耗时。如果每一个项目都自己搞一套配置,肯定会一团糟。我们需要的是一个标准化的 Java 项目管理和构建工具。
Maven 就是是专门为 Java 项目打造的管理和构建工具,它的主要功能有:
一个使用Maven管理的普通的Java项目,它的目录结构默认如下:
1
2
3
4
5
6
7
8
9
10a-maven-project
├── pom.xml
├── src
│ ├── main
│ │ ├── java
│ │ └── resources
│ └── test
│ ├── java
│ └── resources
└── target
项目的根目录 a-maven-project 是项目名,它有一个项目描述文件 pom.xml,存放 Java 源码的目录是 src/main/java,存放资源文件的目录是 src/main/resources,存放测试源码的目录是 src/test/java,存放测试资源的目录是 src/test/resources,最后,所有编译、打包生成的文件都放在 target 目录里。这些就是一个 Maven 项目的标准目录结构。
所有的目录结构都是约定好的标准结构,我们千万不要随意修改目录结构。使用标准结构不需要做任何配置,Maven 就可以正常使用。
我们再来看最关键的一个项目描述文件pom.xml,它的内容长得像下面:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17<project ...>
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>hello</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<properties>
...
</properties>
<dependencies>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
</project>
其中,groupId 类似于 Java 的包名,通常是公司或组织名称,artifactId 类似于 Java 的类名,通常是项目名称,再加上 version,一个 Maven 工程就是由 groupId,artifactId 和 version 作为唯一标识。我们在引用其他第三方库的时候,也是通过这 3 个变量确定。例如,依赖 commons-logging:
1
2
3
4
5<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
使用 <dependency> 声明一个依赖后,Maven 就会自动下载这个依赖包并把它放到 classpath 中。
要安装Maven,可以从Maven官网下载最新的Maven 3.6.x,然后在本地解压,设置几个环境变量:
1
2M2_HOME=/path/to/maven-3.6.x
PATH=$PATH:$M2_HOME/bin
Windows可以把%M2_HOME%\bin添加到系统Path变量中。
然后,打开命令行窗口,输入mvn -version,应该看到Maven的版本信息:
1
2
3
4
5Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: D:\maven\bin\..
Java version: 1.8.0_271, vendor: Oracle Corporation, runtime: D:\Program Files\Java\jdk1.8.0_271\jre
Default locale: zh_CN, platform encoding: GBK
os name: "windows 10", version: "10.0", arch: "amd64", family: "windows"
如果提示命令未找到,说明系统PATH路径有误,需要修复后再运行。
Maven是一个Java项目的管理和构建工具:
如果我们的项目依赖第三方的jar包,例如commons logging,那么问题来了:commons logging发布的jar包在哪下载?
如果我们还希望依赖log4j,那么使用log4j需要哪些jar包?
类似的依赖还包括:JUnit,JavaMail,MySQL驱动等等,一个可行的方法是通过搜索引擎搜索到项目的官网,然后手动下载zip包,解压,放入classpath。但是,这个过程非常繁琐。
Maven解决了依赖管理问题。例如,我们的项目依赖abc这个jar包,而abc又依赖xyz这个jar包:
1
2
3
4
5
6
7
8
9
10
11
12
13┌──────────────┐
│Sample Project│
└──────────────┘
│
▼
┌──────────────┐
│ abc │
└──────────────┘
│
▼
┌──────────────┐
│ xyz │
└──────────────┘
当我们声明了abc的依赖时,Maven自动把abc和xyz都加入了我们的项目依赖,不需要我们自己去研究abc是否需要依赖xyz。
因此,Maven的第一个作用就是解决依赖管理。我们声明了自己的项目需要abc,Maven会自动导入abc的jar包,再判断出abc需要xyz,又会自动导入xyz的jar包,这样,最终我们的项目会依赖abc和xyz两个jar包。
我们来看一个复杂依赖示例:
1
2
3
4
5<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>1.4.2.RELEASE</version>
</dependency>
当我们声明一个 spring-boot-starter-web 依赖时,Maven 会自动解析并判断最终需要大概二三十个其他依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23spring-boot-starter-web
spring-boot-starter
spring-boot
sprint-boot-autoconfigure
spring-boot-starter-logging
logback-classic
logback-core
slf4j-api
jcl-over-slf4j
slf4j-api
jul-to-slf4j
slf4j-api
log4j-over-slf4j
slf4j-api
spring-core
snakeyaml
spring-boot-starter-tomcat
tomcat-embed-core
tomcat-embed-el
tomcat-embed-websocket
tomcat-embed-core
jackson-databind
...
如果我们自己去手动管理这些依赖是非常费时费力的,而且出错的概率很大。
Maven定义了几种依赖关系,分别是 compile、test、runtime 和 provided:
| scope | 说明 | 示例 |
|---|---|---|
| compile | 编译时需要用到该jar包(默认) | commons-logging |
| test | 编译Test时需要用到该jar包 | junit |
| runtime | 编译时不需要,但运行时需要用到 | mysql |
| provided | 编译时需要用到,但运行时由JDK或某个服务器提供 | servlet-api |
其中,默认的 compile 是最常用的,Maven 会把这种类型的依赖直接放入 classpath。
test 依赖表示仅在测试时使用,正常运行时并不需要。最常用的 test 依赖就是 JUnit:
1
2
3
4
5
6<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.3.2</version>
<scope>test</scope>
</dependency>
runtime 依赖表示编译时不需要,但运行时需要。最典型的 runtime 依赖是 JDBC 驱动,例如 MySQL 驱动:
1
2
3
4
5
6<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.48</version>
<scope>runtime</scope>
</dependency>
provided 依赖表示编译时需要,但运行时不需要。最典型的 provided 依赖是 Servlet API,编译的时候需要,但是运行时,Servlet 服务器内置了相关的 jar,所以运行期不需要:
1
2
3
4
5
6<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>4.0.0</version>
<scope>provided</scope>
</dependency>
最后一个问题是,Maven 如何知道从何处下载所需的依赖?也就是相关的 jar 包?答案是 Maven 维护了一个中央仓库(repo1.maven.org),所有第三方库将自身的 jar 以及相关信息上传至中央仓库,Maven 就可以从中央仓库把所需依赖下载到本地。
Maven并不会每次都从中央仓库下载jar包。一个jar包一旦被下载过,就会被Maven自动缓存在本地目录(用户主目录的.m2目录),所以,除了第一次编译时因为下载需要时间会比较慢,后续过程因为有本地缓存,并不会重复下载相同的jar包。
对于某个依赖,Maven只需要3个变量即可唯一确定某个jar包:
通过上述3个变量,即可唯一确定某个jar包。Maven通过对jar包进行PGP签名确保任何一个jar包一经发布就无法修改。修改已发布jar包的唯一方法是发布一个新版本。
因此,某个jar包一旦被Maven下载过,即可永久地安全缓存在本地。
注:只有以
-SNAPSHOT结尾的版本号会被 Maven 视为开发版本,开发版本每次都会重复下载,这种SNAPSHOT版本只能用于内部私有的Maven repo,公开发布的版本不允许出现SNAPSHOT。
除了可以从Maven的中央仓库下载外,还可以从Maven的镜像仓库下载。如果访问Maven的中央仓库非常慢,我们可以选择一个速度较快的Maven的镜像仓库。Maven镜像仓库定期从中央仓库同步:
1
2
3
4
5
6
7
8
9 slow ┌───────────────────┐
┌─────────────>│Maven Central Repo.│
│ └───────────────────┘
│ │
│ │sync
│ ▼
┌───────┐ fast ┌───────────────────┐
│ User │─────────>│Maven Mirror Repo. │
└───────┘ └───────────────────┘
中国区用户可以使用阿里云提供的Maven镜像仓库。使用Maven镜像仓库需要一个配置,在用户主目录下进入.m2目录,创建一个settings.xml配置文件(个人是在安装目录-conf-settings.xml),内容如下:
1
2
3
4
5
6
7
8
9
10
11<settings>
<mirrors>
<mirror>
<id>aliyun</id>
<name>aliyun</name>
<mirrorOf>central</mirrorOf>
<!-- 国内推荐阿里云的Maven镜像 -->
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
</mirrors>
</settings>
配置镜像仓库后,Maven的下载速度就会非常快。
最后一个问题:如果我们要引用一个第三方组件,比如 okhttp,如何确切地获得它的 groupId、artifactId 和 version?方法是通过 search.maven.org 搜索关键字,找到对应的组件后,直接复制。
在命令中,进入到pom.xml所在目录,输入以下命令:
1
mvn clean packages
如果一切顺利,即可在target目录下获得编译后自动打包的jar。
scope 有:compile(默认),test,runtime 和 provided;Maven不但有标准化的项目结构,而且还有一套标准化的构建流程,可以自动化实现编译,打包,发布,等等。
使用Maven时,我们首先要了解什么是Maven的生命周期(lifecycle)。
Maven的生命周期由一系列阶段(phase)构成,以内置的生命周期default为例,它包含以下phase:
如果我们运行 mvn package,Maven 就会执行 default 生命周期,它会从开始一直运行到 package 这个 phase 为止:
如果我们运行 mvn compile,Maven 也会执行 default 生命周期,但这次它只会运行到 compile,即以下几个 phase:
Maven 另一个常用的生命周期是 clean,它会执行 3 个 phase:
所以,我们使用mvn这个命令时,后面的参数是phase,Maven自动根据生命周期运行到指定的phase。
更复杂的例子是指定多个phase,例如,运行mvn clean package,Maven先执行clean生命周期并运行到clean这个phase,然后执行default生命周期并运行到package这个phase,实际执行的phase如下:
在实际开发过程中,经常使用的命令有:
mvn clean:清理所有生成的class和jar;
mvn clean compile:先清理,再执行到compile;
mvn clean test:先清理,再执行到test,因为执行test前必须执行compile,所以这里不必指定compile;
mvn clean package:先清理,再执行到package。
大多数phase在执行过程中,因为我们通常没有在pom.xml中配置相关的设置,所以这些phase什么事情都不做。
经常用到的phase其实只有几个:
clean:清理
compile:编译
test:运行测试
package:打包
执行一个phase又会触发一个或多个goal:
| 执行的Phase | 对应执行的Goal |
|---|---|
| compile | compiler:compile |
| test | compiler:testCompile surefire:test |
goal的命名总是abc:xyz这种形式。 |
其实我们类比一下就明白了:
大多数情况,我们只要指定phase,就默认执行这些phase默认绑定的goal,只有少数情况,我们可以直接指定运行一个goal,例如,启动Tomcat服务器:
1
mvn tomcat:run
Maven通过lifecycle、phase和goal来提供标准的构建流程。
最常用的构建命令是指定phase,然后让Maven执行到指定的phase:
通常情况,我们总是执行phase默认绑定的goal,因此不必指定goal。
我们在前面介绍了 Maven 的 lifecycle,phase 和 goal:使用 Maven 构建项目就是执行 lifecycle,执行到指定的 phase 为止。每个 phase 会执行自己默认的一个或多个 goal。goal 是最小任务单元。
我们以compile这个phase为例,如果执行:
1
mvn compile
Maven将执行compile这个phase,这个phase会调用compiler插件执行关联的compiler:compile这个goal。
实际上,执行每个phase,都是通过某个插件(plugin)来执行的,Maven本身其实并不知道如何执行compile,它只是负责找到对应的compiler插件,然后执行默认的compiler:compile这个goal来完成编译。
所以,使用Maven,实际上就是配置好需要使用的插件,然后通过phase调用它们。
Maven已经内置了一些常用的标准插件:
| 插件名称 | 对应执行的phase | ||
|---|---|---|---|
| clean | clean | ||
| compiler | compile | ||
| surefire | test | ||
| jar | package | ||
如果标准插件无法满足需求,我们还可以使用自定义插件。使用自定义插件的时候,需要声明。例如,使用maven-shade-plugin可以创建一个可执行的jar,要使用这个插件,需要在pom.xml中声明它: |
|||
|
|||
自定义插件往往需要一些配置,例如,maven-shade-plugin需要指定Java程序的入口,它的配置是: |
|||
|
|||
注意,Maven自带的标准插件例如compiler是无需声明的,只有引入其它的插件才需要声明。 |
|||
| 下面列举了一些常用的插件: |
pom.xml中声明插件及配置;phase被执行时执行; 在软件开发中,把一个大项目分拆为多个模块是降低软件复杂度的有效方法:
1
2
3
4
5
6
7
8
9
10
11 ┌ ─ ─ ─ ─ ─ ─ ┐
┌─────────┐
│ │Module A │ │
└─────────┘
┌──────────────┐ split │ ┌─────────┐ │
│Single Project│───────> │Module B │
└──────────────┘ │ └─────────┘ │
┌─────────┐
│ │Module C │ │
└─────────┘
└ ─ ─ ─ ─ ─ ─ ┘
对于Maven工程来说,原来是一个大项目:
1
2
3single-project
├── pom.xml
└── src
现在可以分拆成3个模块:
1
2
3
4
5
6
7
8
9
10mutiple-project
├── module-a
│ ├── pom.xml
│ └── src
├── module-b
│ ├── pom.xml
│ └── src
└── module-c
├── pom.xml
└── src
Maven可以有效地管理多个模块,我们只需要把每个模块当作一个独立的Maven项目,它们有各自独立的pom.xml。例如,模块A的pom.xml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>module-a</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>module-a</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.5.2</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
模块B的pom.xml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>module-b</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>module-b</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.5.2</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
可以看出来,模块A和模块B的pom.xml高度相似,因此,我们可以提取出共同部分作为parent:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>parent</artifactId>
<version>1.0</version>
<packaging>pom</packaging>
<name>parent</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<java.version>11</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.28</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.2.3</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-engine</artifactId>
<version>5.5.2</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>
注意到parent的<packaging>是pom而不是jar,因为parent本身不含任何Java代码。编写parent的pom.xml只是为了在各个模块中减少重复的配置。现在我们的整个工程结构如下:
1
2
3
4
5
6
7
8
9
10
11
12
13multiple-project
├── pom.xml
├── parent
│ └── pom.xml
├── module-a
│ ├── pom.xml
│ └── src
├── module-b
│ ├── pom.xml
│ └── src
└── module-c
├── pom.xml
└── src
这样模块A就可以简化为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>parent</artifactId>
<version>1.0</version>
<relativePath>../parent/pom.xml</relativePath>
</parent>
<artifactId>module-a</artifactId>
<packaging>jar</packaging>
<name>module-a</name>
</project>
模块B、模块C都可以直接从parent继承,大幅简化了pom.xml的编写。
如果模块A依赖模块B,则模块A需要模块B的jar包才能正常编译,我们需要在模块A中引入模块B:
1
2
3
4
5
6
7
8 ...
<dependencies>
<dependency>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>module-b</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
最后,在编译的时候,需要在根目录创建一个pom.xml统一编译:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.itranswarp.learnjava</groupId>
<artifactId>build</artifactId>
<version>1.0</version>
<packaging>pom</packaging>
<name>build</name>
<modules>
<module>parent</module>
<module>module-a</module>
<module>module-b</module>
<module>module-c</module>
</modules>
</project>
这样,在根目录执行mvn clean package时,Maven根据根目录的pom.xml找到包括parent在内的共4个<module>,一次性全部编译。
其实我们使用的大多数第三方模块都是这个用法,例如,我们使用commons logging、log4j这些第三方模块,就是第三方模块的开发者自己把编译好的jar包发布到Maven的中央仓库中。
私有仓库是指公司内部如果不希望把源码和jar包放到公网上,那么可以搭建私有仓库。私有仓库总是在公司内部使用,它只需要在本地的~/.m2/settings.xml中配置好,使用方式和中央仓位没有任何区别。
本地仓库是指把本地开发的项目“发布”在本地,这样其他项目可以通过本地仓库引用它。但是我们不推荐把自己的模块安装到Maven的本地仓库,因为每次修改某个模块的源码,都需要重新安装,非常容易出现版本不一致的情况。更好的方法是使用模块化编译,在编译的时候,告诉Maven几个模块之间存在依赖关系,需要一块编译,Maven就会自动按依赖顺序编译这些模块。
Maven支持模块化管理,可以把一个大项目拆成几个模块:
parent的pom.xml统一定义重复配置;<modules>编译多个模块。 我们使用Maven时,基本上只会用到mvn这一个命令。有些童鞋可能听说过mvnw,这个是啥?
mvnw是Maven Wrapper的缩写。因为我们安装Maven时,默认情况下,系统所有项目都会使用全局安装的这个Maven版本。但是,对于某些项目来说,它可能必须使用某个特定的Maven版本,这个时候,就可以使用Maven Wrapper,它可以负责给这个特定的项目安装指定版本的Maven,而其他项目不受影响。
简单地说,Maven Wrapper就是给一个项目提供一个独立的,指定版本的Maven给它使用。
安装Maven Wrapper最简单的方式是在项目的根目录(即pom.xml所在的目录)下运行安装命令:
1
mvn -N io.takari:maven:0.7.6:wrapper
它会自动使用最新版本的Maven。注意0.7.6是Maven Wrapper的版本。最新的Maven Wrapper版本可以去官方网站查看。
如果要指定使用的Maven版本,使用下面的安装命令指定版本,例如3.3.3:
1
mvn -N io.takari:maven:0.7.6:wrapper -Dmaven=3.3.3
安装后,查看项目结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16my-project
├── .mvn
│ └── wrapper
│ ├── MavenWrapperDownloader.java
│ ├── maven-wrapper.jar
│ └── maven-wrapper.properties
├── mvnw
├── mvnw.cmd
├── pom.xml
└── src
├── main
│ ├── java
│ └── resources
└── test
├── java
└── resources
发现多了 mvnw、mvnw.cmd 和 .mvn 目录,我们只需要把 mvn 命令改成 mvnw 就可以使用跟项目关联的 Maven。例如:
1
mvnw clean package
在Linux或macOS下运行时需要加上./:
1
./mvnw clean package
现代操作系统(Windows,macOS,Linux)都可以执行多任务。多任务就是同时运行多个任务,例如: IE、 QQ、网易云音乐
CPU执行代码都是一条一条顺序执行的,但是,即使是单核cpu,也可以同时运行多个任务。因为操作系统执行多任务实际上就是让CPU对多个任务轮流交替执行。
例如,假设我们有语文、数学、英语3门作业要做,每个作业需要30分钟。我们把这3门作业看成是3个任务,可以做1分钟语文作业,再做1分钟数学作业,再做1分钟英语作业。
这样轮流做下去,在某些人眼里看来,做作业的速度就非常快,看上去就像同时在做3门作业一样。
类似的,操作系统轮流让多个任务交替执行,例如,让浏览器执行0.001秒,让QQ执行0.001秒,再让音乐播放器执行0.001秒,在人看来,CPU就是在同时执行多个任务。
即使是多核CPU,因为通常任务的数量远远多于CPU的核数,所以任务也是交替执行的。
在计算机中,我们把一个任务称为一个进程,浏览器就是一个进程,视频播放器是另一个进程,类似的,音乐播放器和Word都是进程。
某些进程内部还需要同时执行多个子任务。例如,我们在使用Word时,Word可以让我们一边打字,一边进行拼写检查,同时还可以在后台进行打印,我们把子任务称为线程。
进程和线程的关系就是:一个进程可以包含一个或多个线程,但至少会有一个线程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 ┌──────────┐
│Process │
│┌────────┐│
┌──────────┐││ Thread ││┌──────────┐
│Process ││└────────┘││Process │
│┌────────┐││┌────────┐││┌────────┐│
┌──────────┐││ Thread ││││ Thread ││││ Thread ││
│Process ││└────────┘││└────────┘││└────────┘│
│┌────────┐││┌────────┐││┌────────┐││┌────────┐│
││ Thread ││││ Thread ││││ Thread ││││ Thread ││
│└────────┘││└────────┘││└────────┘││└────────┘│
└──────────┘└──────────┘└──────────┘└──────────┘
┌──────────────────────────────────────────────┐
│ Operating System │
└──────────────────────────────────────────────┘
操作系统调度的最小任务单位其实不是进程,而是线程。常用的Windows、Linux等操作系统都采用抢占式多任务,如何调度线程完全由操作系统决定,程序自己不能决定什么时候执行,以及执行多长时间。
因为同一个应用程序,既可以有多个进程,也可以有多个线程,因此,实现多任务的方法,有以下几种:
1 | ┌──────────┐ ┌──────────┐ ┌──────────┐ |
1 | ┌────────────────────┐ |
1 | ┌──────────┐┌──────────┐┌──────────┐ |
进程和线程是包含关系,但是多任务既可以由多进程实现,也可以由单进程内的多线程实现,还可以混合多进程+多线程。
具体采用哪种方式,要考虑到进程和线程的特点。
和多线程相比,多进程的缺点在于:
而多进程的优点在于:
多进程稳定性比多线程高,因为在多进程的情况下,一个进程崩溃不会影响其他进程,而在多线程的情况下,任何一个线程崩溃会直接导致整个进程崩溃。
Java语言内置了多线程支持:一个Java程序实际上是一个JVM进程,JVM进程用一个主线程来执行main()方法,在main()方法内部,我们又可以启动多个线程。此外,JVM还有负责垃圾回收的其他工作线程等。
因此,对于大多数Java程序来说,我们说多任务,实际上是说如何使用多线程实现多任务。
和单线程相比,多线程编程的特点在于:多线程经常需要读写共享数据,并且需要同步。例如,播放电影时,就必须由一个线程播放视频,另一个线程播放音频,两个线程需要协调运行,否则画面和声音就不同步。因此,多线程编程的复杂度高,调试更困难。
Java多线程编程的特点又在于:
因此,必须掌握Java多线程编程才能继续深入学习其他内容。
Java语言内置了多线程支持。当Java程序启动的时候,实际上是启动了一个JVM进程,然后,JVM启动主线程来执行main()方法。在main()方法中,我们又可以启动其他线程。
要创建一个新线程非常容易,我们需要实例化一个Thread实例,然后调用它的start()方法:
1
2
3
4
5
6public class Main {
public static void main(String[] args) {
Thread t = new Thread();
t.start(); // 启动新线程
}
}
但是这个线程启动后实际上什么也不做就立刻结束了。我们希望新线程能执行指定的代码,有以下几种方法:
方法一:从Thread派生一个自定义类,然后覆写run()方法:
1 | public class Main { |
输出
1 | start new thread! |
执行上述代码,注意到 start() 方法会在内部自动调用实例的 run() 方法。
三步走:
- 继承
Thread类- 重写
run()方法- 调用
start()开启线程
方法二:创建 Thread 实例时,传入一个 Runnable 实例:
1 | public class Main { |
输出
1 | start new thread! |
三步走:
- 实现
Runbable接口- 重写
run()方法- 执行进程需要丢入
Runnable接口实现类,调用start()方法
方法三:用 Java8 引入的 lambda 语法进一步简写为:
1 | public class Main { |
使用
lambda简化,其实lambda也相当于实现类
使用线程执行的打印语句,和直接在main()方法执行有区别吗?
区别大了去了。我们看以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13public class Main {
public static void main(String[] args) {
System.out.println("main start..."); // main
Thread t = new Thread() { // main
public void run() {
System.out.println("thread run...");
System.out.println("thread end.");
}
};
t.start(); // main
System.out.println("main end..."); // main
}
}
我们用 // main 表示主线程,也就是 main线程 ,main线程 执行的代码有 4 行,首先打印 main start,然后创建 Thread 对象,紧接着调用 start() 启动新线程。当 start() 方法被调用时,JVM 就创建了一个新线程,我们通过实例变量 t 来表示这个新线程对象,并开始执行。
接着,main 线程继续执行打印 main end 语句,而 t 线程在 main 线程执行的同时会并发执行,打印 thread run 和 thread end 语句。
当 run() 方法结束时,新线程就结束了。而 main() 方法结束时,主线程也结束了。
我们再来看线程的执行顺序:
但是,除了可以肯定,main start 会先打印外,main end 打印在 thread run 之前、thread end 之后或者之间,都无法确定。因为从 t 线程开始运行以后,两个线程就开始同时运行了,并且由操作系统调度,程序本身无法确定线程的调度顺序。
要模拟并发执行的效果,我们可以在线程中调用Thread.sleep(),强迫当前线程暂停一段时间:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public static void main(String[] args) {
System.out.println("main start...");
Thread t = new Thread() {
public void run() {
System.out.println("thread run...");
try {
Thread.sleep(10);
} catch (InterruptedException e) {}
System.out.println("thread end.");
}
};
t.start();
try {
Thread.sleep(20);
} catch (InterruptedException e) {}
System.out.println("main end...");
}
}
sleep() 传入的参数是毫秒。调整暂停时间的大小,我们可以看到 main 线程和 t 线程执行的先后顺序。
要特别注意:直接调用Thread实例的run()方法是无效的:
2
3
4
5
6
7
8
9
10
11
12
public static void main(String[] args) {
Thread t = new MyThread();
t.run();
}
}
class MyThread extends Thread {
public void run() {
System.out.println("hello");
}
}
直接调用 run() 方法,相当于调用了一个普通的 Java 方法,当前线程并没有任何改变,也不会启动新线程。上述代码实际上是在 main() 方法内部又调用了 run() 方法,打印 hello 语句是在 main 线程中执行的,没有任何新线程被创建。
必须调用 Thread 实例的 start() 方法才能启动新线程,如果我们查看 Thread 类的源代码,会看到 start() 方法内部调用了一个private native void start0()方法,native 修饰符表示这个方法是由 JVM 虚拟机内部的 C 代码实现的,不是由 Java 代码实现的。
可以对线程设定优先级,设定优先级的方法是:
1
Thread.setPriority(int n) // 1~10, 默认值5
获取优先级
1
Thread.getPriority()
Note:
Runnable 接口,因为 Java 单继承的局限性好处:
lambda 表达式只有一行代码的情况下才能简化为一行,如果有多行就用代码块包裹| 方法 | 说明 |
|---|---|
setPriority(int new Priority) |
更改线程的优先级 |
static void sleep(long millis) |
在置顶的毫秒数内让当前正在执行的线程休眠 |
void join() |
等待该线程终止 |
static void yield() |
暂停当前正在执行的线程对象,并执行其他的线程 |
void interrupt |
中断线程,别用这个方式 |
boolean isAlive() |
测试线层是否处于活动状态 |
stop()、destroy()方法。【已废弃】flag==false,则终止线程运行sleep(时间) 置顶当前线程阻塞的毫秒数;模拟网络延时:放大问题的发生性
Thread.State
在 Java 程序中,一个线程对象只能调用一次 start() 方法启动新线程,并在新线程中执行 run() 方法。一旦 run() 方法执行完毕,线程就结束了。因此,Java 线程的状态有以下几种:
用一个状态转移图表示如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18 ┌─────────────┐
│ New │
└─────────────┘
│
▼
┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐
┌─────────────┐ ┌─────────────┐
││ Runnable │ │ Blocked ││
└─────────────┘ └─────────────┘
│┌─────────────┐ ┌─────────────┐│
│ Waiting │ │Timed Waiting│
│└─────────────┘ └─────────────┘│
─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─
│
▼
┌─────────────┐
│ Terminated │
└─────────────┘
当线程启动后,它可以在 Runnable、Blocked、Waiting 和 Timed Waiting 这几个状态之间切换,直到最后变成 Terminated 状态,线程终止。
线程终止的原因有:
一个线程还可以等待另一个线程直到其运行结束。例如,main 线程在启动 t 线程后,可以通过 t.join() 等待 t 线程结束后再继续运行:
1
2
3
4
5
6
7
8
9
10
11public class Main {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
System.out.println("hello");
});
System.out.println("start");
t.start();
t.join();
System.out.println("end");
}
}
当 main 线程对线程对象 t 调用 join() 方法时,主线程将等待变量 t 表示的线程运行结束,即 join 就是指等待该线程结束,然后才继续往下执行自身线程。所以,上述代码打印顺序可以肯定是 main 线程先打印 start,t 线程再打印 hello,main 线程最后再打印 end。
如果 t 线程已经结束,对实例 t 调用 join() 会立刻返回。此外,join(long) 的重载方法也可以指定一个等待时间,超过等待时间后就不再继续等待。
如果线程需要执行一个长时间任务,就可能需要能中断线程。中断线程就是其他线程给该线程发一个信号,该线程收到信号后结束执行 run() 方法,使得自身线程能立刻结束运行。
我们举个栗子:假设从网络下载一个 100M 的文件,如果网速很慢,用户等得不耐烦,就可能在下载过程中点 “取消”,这时,程序就需要中断下载线程的执行。
中断一个线程非常简单,只需要在其他线程中对目标线程调用 interrupt() 方法,目标线程需要反复检测自身状态是否是 interrupted 状态,如果是,就立刻结束运行。
我们还是看示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Main {
public static void main(String[] args) throws InterruptedException {
Thread t = new MyThread();
t.start();
Thread.sleep(1); // 暂停1毫秒
t.interrupt(); // 中断t线程
t.join(); // 等待t线程结束
System.out.println("end");
}
}
class MyThread extends Thread {
public void run() {
int n = 0;
while (! isInterrupted()) {
n ++;
System.out.println(n + " hello!");
}
}
}
仔细看上述代码,main 线程通过调用 t.interrupt()方法中断 t 线程,但是要注意,interrupt()方法仅仅向 t 线程发出了 “中断请求”,至于 t 线程是否能立刻响应,要看具体代码。而 t 线程的 while 循环会检测 isInterrupted(),所以上述代码能正确响应 interrupt() 请求,使得自身立刻结束运行 run()方法。
如果线程处于等待状态,例如,t.join()会让 main 线程进入等待状态,此时,如果对 main 线程调用 interrupt(),join()方法会立刻抛出 InterruptedException,因此,目标线程只要捕获到 join()方法抛出的 InterruptedException,就说明有其他线程对其调用了 interrupt()方法,通常情况下该线程应该立刻结束运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39public class Main {
public static void main(String[] args) throws InterruptedException {
Thread t = new MyThread();
t.start();
Thread.sleep(1000);
t.interrupt(); // 中断t线程
t.join(); // 等待t线程结束
System.out.println("end");
}
}
class MyThread extends Thread {
public void run() {
Thread hello = new HelloThread();
hello.start(); // 启动hello线程
try {
hello.join(); // 等待hello线程结束
} catch (InterruptedException e) {
System.out.println("interrupted!");
}
hello.interrupt();
}
}
class HelloThread extends Thread {
public void run() {
int n = 0;
while (!isInterrupted()) {
n++;
System.out.println(n + " hello!");
try {
Thread.sleep(100);
} catch (InterruptedException e) {
System.out.println("InterruptedException");
break;
}
}
}
}
main 线程通过调用 t.interrupt() 从而通知 t 线程中断,而此时 t 线程正位于 hello.join() 的等待中,此方法会立刻结束等待并抛出 InterruptedException。由于我们在 t 线程中捕获了 InterruptedException,因此,就可以准备结束该线程。在 t 线程结束前,对 hello 线程也进行了 interrupt() 调用通知其中断。如果去掉这一行代码,可以发现 hello 线程仍然会继续运行,且 JVM 不会退出。
另一个常用的中断线程的方法是设置标志位。我们通常会用一个 running 标志位来标识线程是否应该继续运行,在外部线程中,通过把 HelloThread.running 置为 false,就可以让线程结束:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Main {
public static void main(String[] args) throws InterruptedException {
HelloThread t = new HelloThread();
t.start();
Thread.sleep(1);
t.running = false; // 标志位置为false
}
}
class HelloThread extends Thread {
public volatile boolean running = true;
public void run() {
int n = 0;
while (running) {
n ++;
System.out.println(n + " hello!");
}
System.out.println("end!");
}
}
注意到 HelloThread 的标志位 boolean running 是一个线程间共享的变量。线程间共享变量需要使用 volatile 关键字标记,确保每个线程都能读取到更新后的变量值。
为什么要对线程间共享的变量用关键字 volatile 声明?这涉及到 Java 的内存模型。在 Java 虚拟机中,变量的值保存在主内存中,但是,当线程访问变量时,它会先获取一个副本,并保存在自己的工作内存中。如果线程修改了变量的值,虚拟机会在某个时刻把修改后的值回写到主内存,但是,这个时间是不确定的!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ┐
Main Memory
│ │
┌───────┐┌───────┐┌───────┐
│ │ var A ││ var B ││ var C │ │
└───────┘└───────┘└───────┘
│ │ ▲ │ ▲ │
─ ─ ─│─│─ ─ ─ ─ ─ ─ ─ ─│─│─ ─ ─
│ │ │ │
┌ ─ ─ ┼ ┼ ─ ─ ┐ ┌ ─ ─ ┼ ┼ ─ ─ ┐
▼ │ ▼ │
│ ┌───────┐ │ │ ┌───────┐ │
│ var A │ │ var C │
│ └───────┘ │ │ └───────┘ │
Thread 1 Thread 2
└ ─ ─ ─ ─ ─ ─ ┘ └ ─ ─ ─ ─ ─ ─ ┘
这会导致如果一个线程更新了某个变量,另一个线程读取的值可能还是更新前的。例如,主内存的变量 a = true,线程 1 执行 a = false 时,它在此刻仅仅是把变量 a 的副本变成了 false,主内存的变量 a 还是 true,在 JVM 把修改后的 a 回写到主内存之前,其他线程读取到的 a 的值仍然是 true,这就造成了多线程之间共享的变量不一致。
因此,volatile 关键字的目的是告诉虚拟机:
volatile关键字解决的是可见性问题:当一个线程修改了某个共享变量的值,其他线程能够立刻看到修改后的值。
如果我们去掉volatile关键字,运行上述程序,发现效果和带volatile差不多,这是因为在x86的架构下,JVM回写主内存的速度非常快,但是,换成ARM的架构,就会有显著的延迟。
Java程序入口就是由JVM启动main线程,main线程又可以启动其他线程。当所有线程都运行结束时,JVM退出,进程结束。
如果有一个线程没有退出,JVM进程就不会退出。所以,必须保证所有线程都能及时结束。
但是有一种线程的目的就是无限循环,例如,一个定时触发任务的线程:
1
2
3
4
5
6
7
8
9
10
11
12
13class TimerThread extends Thread {
public void run() {
while (true) {
System.out.println(LocalTime.now());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
break;
}
}
}
}
如果这个线程不结束,JVM进程就无法结束。问题是,由谁负责结束这个线程?
然而这类线程经常没有负责人来负责结束它们。但是,当其他线程结束时,JVM进程又必须要结束,怎么办?
答案是使用守护线程(Daemon Thread)。
守护线程是指为其他线程服务的线程。在JVM中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出。
因此,JVM退出时,不必关心守护线程是否已结束。
如何创建守护线程呢?方法和普通线程一样,只是在调用start()方法前,调用setDaemon(true)把该线程标记为守护线程:
1
2
3Thread t = new MyThread();
t.setDaemon(true); // 默认是false:表示是用户线程,正常的线程都是用户线程
t.start();
在守护线程中,编写代码要注意:守护线程不能持有任何需要关闭的资源,例如打开文件等,因为虚拟机退出时,守护线程没有任何机会来关闭文件,这会导致数据丢失。
简单定义: 多个线程操作同一个资源
当多个线程同时运行时,线程的调度由操作系统决定,程序本身无法决定。因此,任何一个线程都有可能在任何指令处被操作系统暂停,然后在某个时间段后继续执行。
这个时候,有个单线程模型下不存在的问题就来了:如果多个线程同时读写共享变量,会出现数据不一致的问题。
我们来看一个例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class Main {
public static void main(String[] args) throws Exception {
var add = new AddThread();
var dec = new DecThread();
add.start();
dec.start();
add.join();
dec.join();
System.out.println(Counter.count);
}
}
class Counter {
public static int count = 0;
}
class AddThread extends Thread {
public void run() {
for (int i=0; i<10000; i++) { Counter.count += 1; }
}
}
class DecThread extends Thread {
public void run() {
for (int i=0; i<10000; i++) { Counter.count -= 1; }
}
}
上面的代码很简单,两个线程同时对一个int变量进行操作,一个加10000次,一个减10000次,最后结果应该是0,但是,每次运行,结果实际上都是不一样的。
这是因为对变量进行读取和写入时,结果要正确,必须保证是原子操作。原子操作是指不能被中断的一个或一系列操作。
为何会不安全:由于CPU会使线程进入阻塞状态,使修改资源的操作中断了,但是在这个时候,其他线程开始运行,也修改了这个资源,因此,会造成数据不一致。
例如,对于语句:
1
n = n + 1;
看上去是一行语句,实际上对应了3条指令:
1
2
3ILOAD
IADD
ISTORE
我们假设n的值是100,如果两个线程同时执行n = n + 1,得到的结果很可能不是102,而是101,原因在于:
1
2
3
4
5
6
7
8
9
10
11┌───────┐ ┌───────┐
│Thread1│ │Thread2│
└───┬───┘ └───┬───┘
│ │
│ILOAD (100) │
│ │ILOAD (100)
│ │IADD
│ │ISTORE (101)
│IADD │
│ISTORE (101)│
▼ ▼
如果线程1在执行ILOAD后被操作系统中断,此刻如果线程2被调度执行,它执行ILOAD后获取的值仍然是100,最终结果被两个线程的ISTORE写入后变成了101,而不是期待的102。
这说明多线程模型下,要保证逻辑正确,对共享变量进行读写时,必须保证一组指令以原子方式执行:即某一个线程执行时,其他线程必须等待:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15┌───────┐ ┌───────┐
│Thread1│ │Thread2│
└───┬───┘ └───┬───┘
│ │
│-- lock -- │
│ILOAD (100) │
│IADD │
│ISTORE (101) │
│-- unlock -- │
│ │-- lock --
│ │ILOAD (101)
│ │IADD
│ │ISTORE (102)
│ │-- unlock --
▼ ▼
通过加锁和解锁的操作,就能保证3条指令总是在一个线程执行期间,不会有其他线程会进入此指令区间。即使在执行期线程被操作系统中断执行,其他线程也会因为无法获得锁导致无法进入此指令区间。只有执行线程将锁释放后,其他线程才有机会获得锁并执行。这种加锁和解锁之间的代码块我们称之为临界区(Critical Section),任何时候临界区最多只有一个线程能执行。
可见,保证一段代码的原子性就是通过加锁和解锁实现的。Java程序使用synchronized关键字对一个对象进行加锁:
1
2
3synchronized(lock) {
n = n + 1;
}
synchronized保证了代码块在任意时刻最多只有一个线程能执行。我们把上面的代码用synchronized改写如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36public class Main {
public static void main(String[] args) throws Exception {
var add = new AddThread();
var dec = new DecThread();
add.start();
dec.start();
add.join();
dec.join();
System.out.println(Counter.count);
}
}
class Counter {
public static final Object lock = new Object();
public static int count = 0;
}
class AddThread extends Thread {
public void run() {
for (int i=0; i<10000; i++) {
synchronized(Counter.lock) {
Counter.count += 1;
}
}
}
}
class DecThread extends Thread {
public void run() {
for (int i=0; i<10000; i++) {
synchronized(Counter.lock) {
Counter.count -= 1;
}
}
}
}
注意到代码:
1
2
3synchronized(Counter.lock) { // 获取锁
...
} // 释放锁
它表示用 Counter.lock 实例作为锁,两个线程在执行各自的 synchronized(Counter.lock) { … } 代码块时,必须先获得锁,才能进入代码块进行。执行结束后,在 synchronized 语句块结束会自动释放锁。这样一来,对 Counter.count 变量进行读写就不可能同时进行。上述代码无论运行多少次,最终结果都是 0。
使用 synchronized 解决了多线程同步访问共享变量的正确性问题。但是,它的缺点是带来了性能下降。因为 synchronized 代码块无法并发执行。此外,加锁和解锁需要消耗一定的时间,所以,synchronized 会降低程序的执行效率。
我们来概括一下如何使用 synchronized:
1 | public void add(int m) { |
1 | public class Main { |
1 | public class Main { |
1 | synchronized(Counter.lockStudent) { |
1 | synchronized(Counter.lockTeacher) { |
JVM规范定义了几种原子操作:
long 和 double 是 64 位数据,JVM 没有明确规定 64 位赋值操作是不是一个原子操作,不过在 x64 平台的 JVM 是把 long 和 double 的赋值作为原子操作实现的。
单条原子操作的语句不需要同步。例如:
1
2
3
4
5public void set(int m) {
synchronized(lock) {
this.value = m;
}
}
就不需要同步。
对引用也是类似。例如:
1
2
3public void set(String s) {
this.value = s;
}
上述赋值语句并不需要同步。
但是,如果是多行赋值语句,就必须保证是同步操作,例如:
1
2
3
4
5
6
7
8
9
10class Pair {
int first;
int last;
public void set(int first, int last) {
synchronized(this) {
this.first = first;
this.last = last;
}
}
}
有些时候,通过一些巧妙的转换,可以把非原子操作变为原子操作。例如,上述代码如果改造成:
1
2
3
4
5
6
7class Pair {
int[] pair;
public void set(int first, int last) {
int[] ps = new int[] { first, last };
this.pair = ps;
}
}
就不再需要同步,因为this.pair = ps是引用赋值的原子操作。而语句:
1
int[] ps = new int[] { first, last };
这里的ps是方法内部定义的局部变量,每个线程都会有各自的局部变量,互不影响,并且互不可见,并不需要同步。
我们知道Java程序依靠synchronized对线程进行同步,使用synchronized的时候,锁住的是哪个对象非常重要。
让线程自己选择锁对象往往会使得代码逻辑混乱,也不利于封装。更好的方法是把synchronized逻辑封装起来。例如,我们编写一个计数器如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Counter {
private int count = 0;
public void add(int n) {
synchronized(this) {
count += n;
}
}
public void dec(int n) {
synchronized(this) {
count -= n;
}
}
public int get() {
return count;
}
}
这样一来,线程调用 add()、dec() 方法时,它不必关心同步逻辑,因为 synchronized 代码块在 add()、dec() 方法内部。并且,我们注意到,synchronized 锁住的对象是 this,即当前实例,这又使得创建多个 Counter 实例的时候,它们之间互不影响,可以并发执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18var c1 = Counter();
var c2 = Counter();
// 对c1进行操作的线程:
new Thread(() -> {
c1.add();
}).start();
new Thread(() -> {
c1.dec();
}).start();
// 对c2进行操作的线程:
new Thread(() -> {
c2.add();
}).start();
new Thread(() -> {
c2.dec();
}).start();
现在,对于Counter类,多线程可以正确调用。
如果一个类被设计为允许多线程正确访问,我们就说这个类就是“线程安全”的(thread-safe),上面的Counter类就是线程安全的。Java标准库的java.lang.StringBuffer也是线程安全的。
还有一些不变类,例如String,Integer,LocalDate,它们的所有成员变量都是final,多线程同时访问时只能读不能写,这些不变类也是线程安全的。
最后,类似Math这些只提供静态方法,没有成员变量的类,也是线程安全的。
除了上述几种少数情况,大部分类,例如ArrayList,都是非线程安全的类,我们不能在多线程中修改它们。但是,如果所有线程都只读取,不写入,那么ArrayList是可以安全地在线程间共享的。
没有特殊说明时,一个类默认是非线程安全的。
我们再观察Counter的代码:
1
2
3
4
5
6
7
8public class Counter {
public void add(int n) {
synchronized(this) {
count += n;
}
}
...
}
当我们锁住的是this实例时,实际上可以用synchronized修饰这个方法。下面两种写法是等价的:
1
2
3
4
5public void add(int n) {
synchronized(this) { // 锁住this
count += n;
} // 解锁
}
1
2
3public synchronized void add(int n) { // 锁住this
count += n;
} // 解锁
因此,用synchronized修饰的方法就是同步方法,它表示整个方法都必须用this实例加锁。
我们再思考一下,如果对一个静态方法添加synchronized修饰符,它锁住的是哪个对象?
1
2
3public synchronized static void test(int n) {
...
}
对于 static 方法,是没有 this 实例的,因为 static 方法是针对类而不是实例。但是我们注意到任何一个类都有一个由 JVM 自动创建的 Class 实例,因此,对 static 方法添加 synchronized,锁住的是该类的 Class 实例。上述 synchronized static 方法实际上相当于:
1
2
3
4
5
6
7public class Counter {
public static void test(int n) {
synchronized(Counter.class) {
...
}
}
}
我们再考察Counter的get()方法:
1
2
3
4
5
6
7
8public class Counter {
private int count;
public int get() {
return count;
}
...
}
它没有同步,因为读一个int变量不需要同步。
然而,如果我们把代码稍微改一下,返回一个包含两个int的对象:
1
2
3
4
5
6
7
8
9
10
11
12public class Counter {
private int first;
private int last;
public Pair get() {
Pair p = new Pair();
p.first = first;
p.last = last;
return p;
}
...
}
就必须要同步了。
Java的线程锁是可重入的锁。
什么是可重入的锁?我们还是来看例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class Counter {
private int count = 0;
public synchronized void add(int n) {
if (n < 0) {
dec(-n);
} else {
count += n;
}
}
public synchronized void dec(int n) {
count += n;
}
}
在 Java 中,String 是一个引用类型,它本身也是一个 class。但是,Java 编译器对 String 有特殊处理,即可以直接用 “…” 来表示一个字符串:
1
String s1 = "Hello!";
实际上字符串在 String 内部是通过一个 char[] 数组表示的,因此,按下面的写法也是可以的:
1
String s2 = new String(new char[] {'H', 'e', 'l', 'l', 'o', '!'});
因为 String 太常用了,所以 Java 提供了 "..." 这种字符串字面量表示方法。
Java 字符串的一个重要特点就是字符串不可变。这种不可变性是通过内部的 private final char[] 字段,以及没有任何修改 char[] 的方法实现的。看下例:
1
2
3
4
5
6
7
8public class Main {
public static void main(String[] args) {
String s = "Hello";
System.out.println(s);
s = s.toUpperCase();
System.out.println(s);
}
}
输出
2
HELLO
个人认为:字符串内容没有改变,因为字符串是引用类型,而
s.toUpperCase()是创建了一个新的字符串,再用s指向它。只是原来的字符串无法通过s访问罢了。
当我们想要比较两个字符串是否相同时,要特别注意,我们实际上是想比较字符串的内容是否相同。必须使用 equals() 方法而不能用 ==。
看下例:
1
2
3
4
5
6
7
8public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "hello";
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
输出
1
2true
true
从表面上看,两个字符串用 == 和 equals() 比较都为 true,但实际上那只是 Java 编译器在编译期,会自动把所有相同的字符串当作一个对象放入常量池,自然 s1 和 s2 的引用就是相同的。
所以,这种 == 比较返回 true 纯属巧合。换一种写法,== 比较就会失败:
1
2
3
4
5
6
7
8public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "HELLO".toLowerCase(); // 因为在编译期间,只有 hello 和 HELLO 两个字符串
System.out.println(s1 == s2);
System.out.println(s1.equals(s2));
}
}
输出
1
2false
true
结论:两个字符串比较,必须总是使用
equals()方法。要忽略大小写比较,使用equalsIgnoreCase()方法。String类还提供了多种方法来搜索子串、提取子串。常用的方法有:
是否包含子串
1 | // 是否包含子串: |
注意到 contains() 方法的参数是 CharSequence 而不是 String,因为 CharSequence 是 String 的父类。
搜索子串的更多的例子:
1 | "Hello".indexOf("l"); // 2 |
提取子串
1 | "Hello".substring(2); // "llo" |
注意索引号是从
0开始的
使用 trim() 方法可以移除字符串首尾空白字符。空白字符包括 空格、\t、\r、\n:
1
" \tHello\r\n ".trim(); // "Hello"
注意:
trim()并没有改变字符串的内容,而是返回了一个新字符串。
另一个strip()方法也可以移除字符串首尾空白字符。它和trim()不同的是,类似中文的空格字符\u3000也会被移除:
2
3
" Hello ".stripLeading(); // "Hello "
" Hello ".stripTrailing(); // " Hello"
String还提供了isEmpty()和isBlank()来判断字符串是否为空和空白字符串:
2
3
4
" ".isEmpty(); // false,因为字符串长度不为0
" \n".isBlank(); // true,因为只包含空白字符
" Hello ".isBlank(); // false,因为包含非空白字符
要在字符串中替换子串,有两种方法。一种是根据字符或字符串替换:
1
2
3String s = "hello";
s.replace('l', 'w'); // "hewwo",所有字符'l'被替换为'w'
s.replace("ll", "~~"); // "he~~o",所有子串"ll"被替换为"~
另一种是通过正则表达式替换:
1
2String s = "A,,B;C ,D";
s.replaceAll("[\\,\\;\\s]+", ","); // "A,B,C,D"
要分割字符串,使用 split() 方法,并且传入的也是正则表达式:
1
2String s = "A,B,C,D";
String[] ss = s.split("\\,"); // {"A", "B", "C", "D"}
拼接字符串使用静态方法 join(),它用指定的字符串连接字符串数组:
1
2String[] arr = {"A", "B", "C"};
String s = String.join("***", arr); // "A***B***C"
字符串提供了 formatted() 方法和 format() 静态方法,可以传入其他参数,替换占位符,然后生成新的字符串:
1
2
3
4
5
6
7public class Main {
public static void main(String[] args) {
String s = "Hi %s, your score is %d!";
System.out.println(s.formatted("Alice", 80));
System.out.println(String.format("Hi %s, your score is %.2f!", "Bob", 59.5));
}
}
有几个占位符,后面就传入几个参数。参数类型要和占位符一致。我们经常用这个方法来格式化信息。常用的占位符有:
-%s:显示字符串;
-%d:显示整数;
-%x:显示十六进制整数;
-%f:显示浮点数。
占位符还可以带格式,例如%.2f表示显示两位小数。如果你不确定用啥占位符,那就始终用%s,因为%s可以显示任何数据类型。要查看完整的格式化语法,请参考JDK文档。
要把任意基本类型或引用类型转换为字符串,可以使用静态方法 valueOf()。这是一个重载方法,编译器会根据参数自动选择合适的方法:
1
2
3
4String.valueOf(123); // "123"
String.valueOf(45.67); // "45.67"
String.valueOf(true); // "true"
String.valueOf(new Object()); // 类似java.lang.Object@636be97c
要把字符串转换为其他类型,就需要根据情况。例如,把字符串转换为 int 类型:
1
2int n1 = Integer.parseInt("123"); // 123
int n2 = Integer.parseInt("ff", 16); // 按十六进制转换,255
把字符串转换为 boolean 类型:
1
2boolean b1 = Boolean.parseBoolean("true"); // true
boolean b2 = Boolean.parseBoolean("FALSE"); // false
要特别注意,Integer 有个 getInteger(String) 方法,它不是将字符串转换为 int,而是把该字符串对应的系统变量转换为 Integer:
1
Integer.getInteger("java.version"); // 版本号,11
String 和 char[] 类型可以互相转换,方法是:
1
2char[] cs = "Hello".toCharArray(); // String -> char[]
String s = new String(cs); // char[] -> String
如果修改了 char[] 数组,String 并不会改变:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
char[] cs = "Hello".toCharArray();
String s = new String(cs);
System.out.println(s);
cs[0] = 'X';
System.out.println(s);
}
}
这是因为通过 new String(char[]) 创建新的 String 实例时,它并不会直接引用传入的 char[] 数组,而是会复制一份,所以,修改外部的 char[] 数组不会影响 String 实例内部的 char[] 数组,因为这是两个不同的数组。
从 String 的不变性设计可以看出,如果传入的对象有可能改变,我们需要复制而不是直接引用。
Java 编译器对 String 做了特殊处理,使得我们可以直接用 + 拼接字符串。
1
2
3
4String s = "";
for (int i = 0; i < 1000; i++) {
s = s + "," + i;
}
虽然可以直接拼接字符串,但是,在循环中,每次循环都会创建新的字符串对象,然后扔掉旧的字符串。这样,绝大部分字符串都是临时对象,不但浪费内存,还会影响 GC 效率。
为了能高效拼接字符串,Java 标准库提供了 StringBuilder,它是一个可变对象,可以预分配缓冲区,这样,往 StringBuilder 中新增字符时,不会创建新的临时对象:
1
2
3
4
5
6StringBuilder sb = new StringBuilder(1024);
for (int i = 0; i < 1000; i++) {
sb.append(',');
sb.append(i);
}
String s = sb.toString();
StringBuilder 还可以进行链式操作:
1
2
3
4
5
6
7
8
9
10public class Main {
public static void main(String[] args) {
var sb = new StringBuilder(1024);
sb.append("Mr ")
.append("Bob")
.append("!")
.insert(0, "Hello, ");
System.out.println(sb.toString());
}
}
如果我们查看 StringBuilder 的源码,可以发现,进行链式操作的关键是,定义的 append() 方法会返回 this,这样,就可以不断调用自身的其他方法。
仿照 StringBuilder,我们也可以设计支持链式操作的类。例如,一个可以不断增加的计数器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class Main {
public static void main(String[] args) {
Adder adder = new Adder();
adder.add(3)
.add(5)
.inc()
.add(10);
System.out.println(adder.value());
}
}
class Adder {
private int sum = 0;
public Adder add(int n) {
sum += n;
return this;
}
public Adder inc() {
sum ++;
return this;
}
public int value() {
return sum;
}
}
注意:对于普通的字符串
+操作,并不需要我们将其改写为StringBuilder,因为 Java 编译器在编译时就自动把多个连续的 + 操作编码为StringConcatFactory的操作。在运行期,StringConcatFactory会自动把字符串连接操作优化为数组复制或者 StringBuilder 操作。
你可能还听说过 StringBuffer,这是 Java 早期的一个 StringBuilder 的线程安全版本,它通过同步来保证多个线程操作 StringBuffer 也是安全的,但是同步会带来执行速度的下降。
StringBuilder 和 StringBuffer 接口完全相同,现在完全没有必要使用 StringBuffer。
要高效拼接字符串,应该使用 StringBuilder。
很多时候,我们拼接的字符串像这样:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Main {
public static void main(String[] args) {
String[] names = {"Bob", "Alice", "Grace"};
var sb = new StringBuilder();
sb.append("Hello ");
for (String name : names) {
sb.append(name).append(", ");
}
// 注意去掉最后的", ":
sb.delete(sb.length() - 2, sb.length());
sb.append("!");
System.out.println(sb.toString());
}
}
类似用分隔符拼接数组的需求很常见,所以 Java 标准库还提供了一个 StringJoiner 来干这个事:
1
2
3
4
5
6
7
8
9
10
11
12import java.util.StringJoiner;
public class Main {
public static void main(String[] args) {
String[] names = {"Bob", "Alice", "Grace"};
var sj = new StringJoiner(", ");
for (String name : names) {
sj.add(name);
}
System.out.println(sj.toString());
}
}
慢着!用 StringJoiner 的结果少了前面的 "Hello" 和结尾的 "!" 遇到这种情况,需要给 StringJoiner 指定 “开头” 和“结尾”:
1
2
3
4
5
6
7
8
9
10public class Main {
public static void main(String[] args) {
String[] names = {"Bob", "Alice", "Grace"};
var sj = new StringJoiner(", ", "Hello ", "!");
for (String name : names) {
sj.add(name);
}
System.out.println(sj.toString());
}
}
String 还提供了一个静态方法 join(),这个方法在内部使用了 StringJoiner 来拼接字符串,在不需要指定 “开头” 和“结尾”的时候,用 String.join() 更方便:
1
2String[] names = {"Bob", "Alice", "Grace"};
var s = String.join(", ", names);
我们已经知道,Java的数据类型分两种:
byte,short,int,long,boolean,float,double,charclass 和 interface 类型 引用类型可以赋值为 null,表示空,但基本类型不能赋值为 null:
1
2String s = null;
int n = null; // compile error!
那么,如何把一个基本类型视为对象(引用类型)?
比如,想要把 int 基本类型变成一个引用类型,我们可以定义一个 Integer 类,它只包含一个实例字段 int,这样,Integer 类就可以视为 int 的包装类(Wrapper Class):
1
2
3
4
5
6
7
8
9
10
11public class Integer {
private int value;
public Integer(int value) {
this.value = value;
}
public int intValue() {
return this.value;
}
}
定义好了 Integer 类,我们就可以把 int 和 Integer 互相转换:
1
2
3Integer n = null;
Integer n2 = new Integer(99);
int n3 = n2.intValue();
实际上,因为包装类型非常有用,Java 核心库为每种基本类型都提供了对应的包装类型:
| 基本类型 | 对应的引用类型 | ||
|---|---|---|---|
| boolean | java.lang.Boolean | ||
| byte | java.lang.Byte | ||
| short | java.lang.Short | ||
| int | java.lang.Integer | ||
| long | java.lang.Long | ||
| float | java.lang.Float | ||
| double | java.lang.Double | ||
| char | java.lang.Character | ||
| 我们可以直接使用,并不需要自己去定义: | |||
|
因为int和Integer可以互相转换:
1
2
3int i = 100;
Integer n = Integer.valueOf(i);
int x = n.intValue();
所以,Java 编译器可以帮助我们自动在 int 和 Integer 之间转型:
1
2Integer n = 100; // 编译器自动使用Integer.valueOf(int)
int x = n; // 编译器自动使用Integer.intValue()
这种直接把 int 变为 Integer 的赋值写法,称为自动装箱(Auto Boxing),反过来,把 Integer 变为 int 的赋值写法,称为自动拆箱(Auto Unboxing)。
注意:自动装箱和自动拆箱只发生在编译阶段,目的是为了少写代码。
装箱和拆箱会影响代码的执行效率,因为编译后的 class 代码是严格区分基本类型和引用类型的。并且,自动拆箱执行时可能会报 NullPointerException:
1
2
3
4
5
6public class Main {
public static void main(String[] args) {
Integer n = null;
int i = n;
}
}
所有的包装类型都是不变类。我们查看 Integer 的源码可知,它的核心代码如下:
1
2
3public final class Integer {
private final int value;
}
因此,一旦创建了 Integer 对象,该对象就是不变的。
对两个 Integer 实例进行比较要特别注意:绝对不能用 == 比较,因为 Integer 是引用类型,必须使用 equals() 比较:
1
2
3
4
5
6
7
8
9
10
11
12public class Main {
public static void main(String[] args) {
Integer x = 127;
Integer y = 127;
Integer m = 99999;
Integer n = 99999;
System.out.println("x == y: " + (x==y)); // true
System.out.println("m == n: " + (m==n)); // false
System.out.println("x.equals(y): " + x.equals(y)); // true
System.out.println("m.equals(n): " + m.equals(n)); // true
}
}
仔细观察结果的童鞋可以发现,== 比较,较小的两个相同的 Integer 返回 true,较大的两个相同的 Integer 返回 false,这是因为 Integer 是不变类,编译器把 Integer x = 127; 自动变为 Integer x = Integer.valueOf(127);,为了节省内存,Integer.valueOf()对于较小的数,始终返回相同的实例,因此,== 比较 “恰好” 为 true,但我们绝不能因为 Java 标准库的 Integer 内部有缓存优化就用 == 比较,必须用 equals()方法比较两个 Integer。
按照语义编程,而不是针对特定的底层实现去“优化”。
因为 Integer.valueOf() 可能始终返回同一个 Integer 实例,因此,在我们自己创建 Integer 的时候,以下两种方法:
Integer n = new Integer(100);Integer n = Integer.valueOf(100);方法 2 更好,因为方法 1 总是创建新的 Integer 实例,方法 2 把内部优化留给 Integer 的实现者去做,即使在当前版本没有优化,也有可能在下一个版本进行优化。
我们把能创建 “新” 对象的静态方法称为静态工厂方法。Integer.valueOf()就是静态工厂方法,它尽可能地返回缓存的实例以节省内存。
创建新对象时,优先选用静态工厂方法而不是
new操作符
如果我们考察 Byte.valueOf() 方法的源码,可以看到,标准库返回的 Byte 实例全部是缓存实例,但调用者并不关心静态工厂方法以何种方式创建新实例还是直接返回缓存的实例。
Integer 类本身还提供了大量方法,例如,最常用的静态方法 parseInt() 可以把字符串解析成一个整数:
1
2int x1 = Integer.parseInt("100"); // 100
int x2 = Integer.parseInt("100", 16); // 256,因为按16进制解析
Integer还可以把整数格式化为指定进制的字符串:
1
2
3
4
5
6
7
8
9public class Main {
public static void main(String[] args) {
System.out.println(Integer.toString(100)); // "100",表示为10进制
System.out.println(Integer.toString(100, 36)); // "2s",表示为36进制
System.out.println(Integer.toHexString(100)); // "64",表示为16进制
System.out.println(Integer.toOctalString(100)); // "144",表示为8进制
System.out.println(Integer.toBinaryString(100)); // "1100100",表示为2进制
}
}
注意:上述方法的输出都是String,在计算机内存中,只用二进制表示,不存在十进制或十六进制的表示方法。int n = 100在内存中总是以4字节的二进制表示:
我们经常使用的 System.out.println(n); 是依靠核心库自动把整数格式化为 10 进制输出并显示在屏幕上,使用 Integer.toHexString(n) 则通过核心库自动把整数格式化为 16 进制。
这里我们注意到程序设计的一个重要原则:数据的存储和显示要分离。
Java 的包装类型还定义了一些有用的静态变量
1
2
3
4
5
6
7
8
9// boolean只有两个值true/false,其包装类型只需要引用Boolean提供的静态字段:
Boolean t = Boolean.TRUE;
Boolean f = Boolean.FALSE;
// int可表示的最大/最小值:
int max = Integer.MAX_VALUE; // 2147483647
int min = Integer.MIN_VALUE; // -2147483648
// long类型占用的bit和byte数量:
int sizeOfLong = Long.SIZE; // 64 (bits)
int bytesOfLong = Long.BYTES; // 8 (bytes)
最后,所有的整数和浮点数的包装类型都继承自 Number,因此,可以非常方便地直接通过包装类型获取各种基本类型:
1
2
3
4
5
6
7
8// 向上转型为Number:
Number num = new Integer(999);
// 获取byte, int, long, float, double:
byte b = num.byteValue();
int n = num.intValue();
long ln = num.longValue();
float f = num.floatValue();
double d = num.doubleValue();
在 Java 中,并没有无符号整型(Unsigned)的基本数据类型。byte、short、int 和 long 都是带符号整型,最高位是符号位。而 C 语言则提供了 CPU 支持的全部数据类型,包括无符号整型。无符号整型和有符号整型的转换在 Java 中就需要借助包装类型的静态方法完成。
例如,byte 是有符号整型,范围是 -128~+127,但如果把 byte 看作无符号整型,它的范围就是 0~255。我们把一个负的 byte 按无符号整型转换为 int:
1
2
3
4
5
6
7
8public class Main {
public static void main(String[] args) {
byte x = -1;
byte y = 127;
System.out.println(Byte.toUnsignedInt(x)); // 255
System.out.println(Byte.toUnsignedInt(y)); // 127
}
}
因为 byte 的 -1 的二进制表示是 11111111,以无符号整型转换后的 int 就是 255。
类似的,可以把一个 short 按 unsigned 转换为 int,把一个 int 按 unsigned 转换为 long。
class;(JDK>=1.5);NullPointerException;equals();Number; 在 Java 中,有很多 class 的定义都符合这样的规范:
private 实例字段;public 方法来读写实例字段。 例如:
1
2
3
4
5
6
7
8
9
10public class Person {
private String name;
private int age;
public String getName() { return this.name; }
public void setName(String name) { this.name = name; }
public int getAge() { return this.age; }
public void setAge(int age) { this.age = age; }
}
如果读写方法符合以下这种命名规范:
1
2
3
4// 读方法:
public Type getXyz()
// 写方法:
public void setXyz(Type value)
那么这种 class 被称为 JavaBean:
上面的字段是 xyz,那么读写方法名分别以 get 和 set 开头,并且后接大写字母开头的字段名 Xyz,因此两个读写方法名分别是 getXyz() 和 setXyz()。
boolean 字段比较特殊,它的读方法一般命名为 isXyz():
1
2
3
4// 读方法:
public boolean isChild()
// 写方法:
public void setChild(boolean value)
我们通常把一组对应的读方法(getter)和写方法(setter)称为属性(property)。例如,name属性
只有getter的属性称为只读属性(read-only),例如,定义一个age只读属性:
类似的,只有setter的属性称为只写属性(write-only)。
很明显,只读属性很常见,只写属性不常见。
属性只需要定义getter和setter方法,不一定需要对应的字段。例如,child只读属性定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Person {
private String name;
private int age;
public String getName() { return this.name; }
public void setName(String name) { this.name = name; }
public int getAge() { return this.age; }
public void setAge(int age) { this.age = age; }
public boolean isChild() {
return age <= 6;
}
}
1 | public class Main { |
输出
1
2
3
4
5
6
7
8
9
10
11
12age
public int Person.getAge()
public void Person.setAge(int)
child
public boolean Person.isChild()
null
class
public final native java.lang.Class java.lang.Object.getClass()
null
name
public java.lang.String Person.getName()
public void Person.setName(java.lang.String)
在Java中,我们可以通过static final来定义常量。例如,我们希望定义周一到周日这7个常量,可以用7个不同的int表示:
1
2
3
4
5
6
7
8
9public class Weekday {
public static final int SUN = 0;
public static final int MON = 1;
public static final int TUE = 2;
public static final int WED = 3;
public static final int THU = 4;
public static final int FRI = 5;
public static final int SAT = 6;
}
使用常量的时候,可以这么引用:
1
2
3if (day == Weekday.SAT || day == Weekday.SUN) {
// TODO: work at home
}
也可以把常量定义为字符串类型,例如,定义3种颜色的常量:
1
2
3
4
5public class Color {
public static final String RED = "r";
public static final String GREEN = "g";
public static final String BLUE = "b";
}
使用常量的时候,可以这么引用:
1
2
3
4String color = ...
if (Color.RED.equals(color)) {
// TODO:
}
无论是int常量还是String常量,使用这些常量来表示一组枚举值的时候,有一个严重的问题就是,编译器无法检查每个值的合理性。例如:
1
2
3
4
5if (weekday == 6 || weekday == 7) {
if (tasks == Weekday.MON) {
// TODO:
}
}
上述代码编译和运行均不会报错,但存在两个问题:
为了让编译器能自动检查某个值在枚举的集合内,并且,不同用途的枚举需要不同的类型来标记,不能混用,我们可以使用 enum 来定义枚举类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
if (day == Weekday.SAT || day == Weekday.SUN) {
System.out.println("Work at home!");
} else {
System.out.println("Work at office!");
}
}
}
enum Weekday {
SUN, MON, TUE, WED, THU, FRI, SAT;
}
注意到定义枚举类是通过关键字enum实现的,我们只需依次列出枚举的常量名。
和int定义的常量相比,使用enum定义枚举有如下好处:
首先,enum常量本身带有类型信息,即Weekday.SUN类型是Weekday,编译器会自动检查出类型错误。例如,下面的语句不可能编译通过:
1
2
3int day = 1;
if (day == Weekday.SUN) { // Compile error: bad operand types for binary operator '=='
}
其次,不可能引用到非枚举的值,因为无法通过编译。
最后,不同类型的枚举不能互相比较或者赋值,因为类型不符。例如,不能给一个Weekday枚举类型的变量赋值为Color枚举类型的值:
1
2Weekday x = Weekday.SUN; // ok!
Weekday y = Color.RED; // Compile error: incompatible types
这就使得编译器可以在编译期自动检查出所有可能的潜在错误。
使用 enum 定义的枚举类是一种引用类型。前面我们讲到,引用类型比较,要使用 equals() 方法,如果使用 == 比较,它比较的是两个引用类型的变量是否是同一个对象。因此,引用类型比较,要始终使用 equals() 方法,但 enum 类型可以例外。
这是因为 enum 类型的每个常量在 JVM 中只有一个唯一实例,所以可以直接用 == 比较:
1
2
3
4if (day == Weekday.FRI) { // ok!
}
if (day.equals(Weekday.SUN)) { // ok, but more code!
}
通过enum定义的枚举类,和其他的class有什么区别?
答案是没有任何区别。enum定义的类型就是class,只不过它有以下几个特点:
定义的enum类型总是继承自java.lang.Enum,且无法被继承;
例如,我们定义的Color枚举类:
1
2
3public enum Color {
RED, GREEN, BLUE;
}
编译器编译出的class大概就像这样:
1
2
3
4
5
6
7
8public final class Color extends Enum { // 继承自Enum,标记为final class
// 每个实例均为全局唯一:
public static final Color RED = new Color();
public static final Color GREEN = new Color();
public static final Color BLUE = new Color();
// private构造方法,确保外部无法调用new操作符:
private Color() {}
}
所以,编译后的 enum 类和普通 class 并没有任何区别。但是我们自己无法按定义普通 class 那样来定义 enum,必须使用 enum 关键字,这是 Java 语法规定的。
因为 enum 是一个 class,每个枚举的值都是 class 实例,因此,这些实例有一些方法:
返回常量名,例如:
1
String s = Weekday.SUN.name(); // "SUN"
返回定义的常量的顺序,从0开始计数,例如:
1
int n = Weekday.MON.ordinal(); // 1
改变枚举常量定义的顺序就会导致ordinal()返回值发生变化。例如:
1 | public enum Weekday { |
和
1
2
3public enum Weekday {
MON, TUE, WED, THU, FRI, SAT, SUN;
}
的 ordinal 就是不同的。如果在代码中编写了类似 if(x.ordinal()==1) 这样的语句,就要保证 enum 的枚举顺序不能变。新增的常量必须放在最后。
Weekday的枚举常量如果要和int转换,使用ordinal()不是非常方便?比如这样写:
1
2String task = Weekday.MON.ordinal() + "/ppt";
saveToFile(task);
但是,如果不小心修改了枚举的顺序,编译器是无法检查出这种逻辑错误的。要编写健壮的代码,就不要依靠 ordinal() 的返回值。因为 enum 本身是 class,所以我们可以定义 private 的构造方法,并且,给每个枚举常量添加字段:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
if (day.dayValue == 6 || day.dayValue == 0) {
System.out.println("Work at home!");
} else {
System.out.println("Work at office!");
}
}
}
enum Weekday {
MON(1), TUE(2), WED(3), THU(4), FRI(5), SAT(6), SUN(0);
public final int dayValue;
private Weekday(int dayValue) {
this.dayValue = dayValue;
}
}
这样就无需担心顺序的变化,新增枚举常量时,也需要指定一个int值。
枚举类的字段也可以是非final类型,即可以在运行期修改,但是不推荐这样做!
默认情况下,对枚举常量调用toString()会返回和name()一样的字符串。但是,toString()可以被覆写,而name()则不行。我们可以给Weekday添加toString()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
if (day.dayValue == 6 || day.dayValue == 0) {
System.out.println("Today is " + day + ". Work at home!");
} else {
System.out.println("Today is " + day + ". Work at office!");
}
}
}
enum Weekday {
MON(1, "星期一"), TUE(2, "星期二"), WED(3, "星期三"), THU(4, "星期四"), FRI(5, "星期五"), SAT(6, "星期六"), SUN(0, "星期日");
public final int dayValue;
private final String chinese;
private Weekday(int dayValue, String chinese) {
this.dayValue = dayValue;
this.chinese = chinese;
}
public String toString() {
return this.chinese;
}
}
覆写toString()的目的是在输出时更有可读性。
判断枚举常量的名字,要始终使用name()方法,绝不能调用toString()!
最后,枚举类可以应用在switch语句中。因为枚举类天生具有类型信息和有限个枚举常量,所以比int、String类型更适合用在switch语句中:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
switch(day) {
case MON:
case TUE:
case WED:
case THU:
case FRI:
System.out.println("Today is " + day + ". Work at office!");
break;
case SAT:
case SUN:
System.out.println("Today is " + day + ". Work at home!");
break;
default:
throw new RuntimeException("cannot process " + day);
}
}
}
enum Weekday {
MON, TUE, WED, THU, FRI, SAT, SUN;
}
- case语句中只能写枚举类定义的变量名称,不能加类名。
- 加上default语句,可以在漏写某个枚举常量时自动报错,从而及时发现错误。
final class Xxx extends Enum {…};name() 获取常量定义的字符串,注意不要使用 toString();ordinal() 返回常量定义的顺序(无实质意义);enum 编写构造方法、字段和方法enum 的构造方法要声明为 private,字段强烈建议声明为 final;enum 适合用在 switch 语句中。 在 Java 中,由 CPU 原生提供的整型最大范围是 64 位 long 型整数。使用 long 型整数可以直接通过 CPU 指令进行计算,速度非常快。
如果我们使用的整数范围超过了 long 型怎么办?这个时候,就只能用软件来模拟一个大整数。java.math.BigInteger 就是用来表示任意大小的整数。BigInteger 内部用一个 int[] 数组来模拟一个非常大的整数:
1
2BigInteger bi = new BigInteger("1234567890");
System.out.println(bi.pow(5)); // 2867971860299718107233761438093672048294900000
对 BigInteger 做运算的时候,只能使用实例方法,例如,加法运算:
1
2
3BigInteger i1 = new BigInteger("1234567890");
BigInteger i2 = new BigInteger("12345678901234567890");
BigInteger sum = i1.add(i2); // 12345678902469135780
和 long 型整数运算比,BigInteger 不会有范围限制,但缺点是速度比较慢。
也可以把BigInteger转换成long型:
1
2
3BigInteger i = new BigInteger("123456789000");
System.out.println(i.longValue()); // 123456789000
System.out.println(i.multiply(i).longValueExact()); // java.lang.ArithmeticException: BigInteger out of long range
使用 longValueExact() 方法时,如果超出了 long 型的范围,会抛出 ArithmeticException。
BigInteger 和 Integer、Long 一样,也是不可变类,并且也继承自 Number 类。因为 Number 定义了转换为基本类型的几个方法:
byte:byteValue()short:shortValue()int:intValue()long:longValue()float:floatValue()double:doubleValue() 因此,通过上述方法,可以把 BigInteger 转换成基本类型。如果 BigInteger 表示的范围超过了基本类型的范围,转换时将丢失高位信息,即结果不一定是准确的。如果需要准确地转换成基本类型,可以使用 intValueExact()、longValueExact() 等方法,在转换时如果超出范围,将直接抛出 ArithmeticException 异常。
如果BigInteger的值甚至超过了float的最大范围(3.4x1038),那么返回的float是什么呢?
1
2
3
4
5
6
7
8
9import java.math.BigInteger;
public class Main {
public static void main(String[] args) {
BigInteger n = new BigInteger("999999").pow(99);
float f = n.floatValue();
System.out.println(f);
}
}
BigInteger 用于表示任意大小的整数;BigInteger 是不变类,并且继承自 Number;BigInteger 转换成基本类型时可使用 longValueExact() 等方法保证结果准确。 和 BigInteger 类似,BigDecimal 可以表示一个任意大小且精度完全准确的浮点数。
1
2BigDecimal bd = new BigDecimal("123.4567");
System.out.println(bd.multiply(bd)); // 15241.55677489
BigDecimal 用 scale() 表示小数位数,例如:
1
2
3
4
5
6BigDecimal d1 = new BigDecimal("123.45");
BigDecimal d2 = new BigDecimal("123.4500");
BigDecimal d3 = new BigDecimal("1234500");
System.out.println(d1.scale()); // 2,两位小数
System.out.println(d2.scale()); // 4
System.out.println(d3.scale()); // 0
通过 BigDecimal 的 stripTrailingZeros() 方法,可以将一个 BigDecimal 格式化为一个相等的,但去掉了末尾 0 的 BigDecimal:
1
2
3
4
5
6
7
8
9BigDecimal d1 = new BigDecimal("123.4500");
BigDecimal d2 = d1.stripTrailingZeros();
System.out.println(d1.scale()); // 4
System.out.println(d2.scale()); // 2,因为去掉了00
BigDecimal d3 = new BigDecimal("1234500");
BigDecimal d4 = d3.stripTrailingZeros();
System.out.println(d3.scale()); // 0
System.out.println(d4.scale()); // -2
如果一个 BigDecimal 的 scale() 返回负数,例如,-2,表示这个数是个整数,并且末尾有 2 个 0。
可以对一个 BigDecimal 设置它的 scale,如果精度比原始值低,那么按照指定的方法进行四舍五入或者直接截断:
1
2
3
4
5
6
7
8
9
10
11
12import java.math.BigDecimal;
import java.math.RoundingMode;
public class Main {
public static void main(String[] args) {
BigDecimal d1 = new BigDecimal("123.456789");
BigDecimal d2 = d1.setScale(4, RoundingMode.HALF_UP); // 四舍五入,123.4568
BigDecimal d3 = d1.setScale(4, RoundingMode.DOWN); // 直接截断,123.4567
System.out.println(d2);
System.out.println(d3);
}
}
对 BigDecimal 做加、减、乘时,精度不会丢失,但是做除法时,存在无法除尽的情况,这时,就必须指定精度以及如何进行截断:
1
2
3
4BigDecimal d1 = new BigDecimal("123.456");
BigDecimal d2 = new BigDecimal("23.456789");
BigDecimal d3 = d1.divide(d2, 10, RoundingMode.HALF_UP); // 保留10位小数并四舍五入
BigDecimal d4 = d1.divide(d2); // 报错:ArithmeticException,因为除不尽
还可以对 BigDecimal 做除法的同时求余数:
1
2
3
4
5
6
7
8
9
10
11import java.math.BigDecimal;
public class Main {
public static void main(String[] args) {
BigDecimal n = new BigDecimal("12.345");
BigDecimal m = new BigDecimal("0.12");
BigDecimal[] dr = n.divideAndRemainder(m);
System.out.println(dr[0]); // 102
System.out.println(dr[1]); // 0.105
}
}
调用 divideAndRemainder() 方法时,返回的数组包含两个 BigDecimal,分别是商和余数,其中商总是整数,余数不会大于除数。我们可以利用这个方法判断两个 BigDecimal 是否是整数倍数:
1
2
3
4
5
6BigDecimal n = new BigDecimal("12.75");
BigDecimal m = new BigDecimal("0.15");
BigDecimal[] dr = n.divideAndRemainder(m);
if (dr[1].signum() == 0) {
// n是m的整数倍
}
在比较两个 BigDecimal 的值是否相等时,要特别注意,使用 equals() 方法不但要求两个 BigDecimal 的值相等,还要求它们的 scale() 相等:
1
2
3
4
5BigDecimal d1 = new BigDecimal("123.456");
BigDecimal d2 = new BigDecimal("123.45600");
System.out.println(d1.equals(d2)); // false,因为scale不同
System.out.println(d1.equals(d2.stripTrailingZeros())); // true,因为d2去除尾部0后scale变为2
System.out.println(d1.compareTo(d2)); // 0
必须使用 compareTo() 方法来比较,它根据两个值的大小分别返回负数、正数和 0,分别表示小于、大于和等于。
总是使用
compareTo()比较两个BigDecimal的值,不要使用equals()
如果查看 BigDecimal 的源码,可以发现,实际上一个 BigDecimal 是通过一个 BigInteger 和一个 scale 来表示的,即 BigInteger 表示一个完整的整数,而 scale 表示小数位数:
1
2
3
4public class BigDecimal extends Number implements Comparable<BigDecimal> {
private final BigInteger intVal;
private final int scale;
}
BigDecimal 也是从 Number 继承的,也是不可变对象。
Java的核心库提供了大量的现成的类供我们使用。本节我们介绍几个常用的工具类。
顾名思义,Math类就是用来进行数学计算的,它提供了大量的静态方法来便于我们实现数学计算:
1 | Math.abs(-100); // 100 |
1 | Math.max(100, 99); // 100 |
1 | Math.pow(2, 10); // 2的10次方=1024 |
1 | Math.sqrt(2); // 1.414... |
1 | Math.exp(2); // 7.389... |
1 | Math.log(4); // 1.386... |
1 | Math.log10(100); // 2 |
1 | Math.sin(3.14); // 0.00159... |
1 | double pi = Math.PI; // 3.14159... |
0 <= x < 1:1 | Math.random(); // 0.53907...每次都不一样 |
Math.random() 实现,计算如下:1 | // 区间在[MIN, MAX)的随机数 |
Java 标准库还提供了一个 StrictMath,它提供了和 Math 几乎一模一样的方法。这两个类的区别在于,由于浮点数计算存在误差,不同的平台(例如 x86 和 ARM)计算的结果可能不一致(指误差不同),因此,StrictMath 保证所有平台计算结果都是完全相同的,而 Math 会尽量针对平台优化计算速度,所以,绝大多数情况下,使用 Math 就足够了。
Random 用来创建伪随机数。所谓伪随机数,是指只要给定一个初始的种子,产生的随机数序列是完全一样的。
要生成一个随机数,可以使用 nextInt()、nextLong()、nextFloat()、nextDouble():
1
2
3
4
5
6Random r = new Random();
r.nextInt(); // 2071575453,每次都不一样
r.nextInt(10); // 5,生成一个[0,10)之间的int
r.nextLong(); // 8811649292570369305,每次都不一样
r.nextFloat(); // 0.54335...生成一个[0,1)之间的float
r.nextDouble(); // 0.3716...生成一个[0,1)之间的double
每次运行程序,生成的随机数都是不同的,没看出伪随机数的特性来。
这是因为我们创建Random实例时,如果不给定种子,就使用系统当前时间戳作为种子,因此每次运行时,种子不同,得到的伪随机数序列就不同。
如果我们在创建Random实例时指定一个种子,就会得到完全确定的随机数序列:
1
2
3
4
5
6
7
8
9
10
11import java.util.Random;
public class Main {
public static void main(String[] args) {
Random r = new Random(12345);
for (int i = 0; i < 10; i++) {
System.out.println(r.nextInt(100));
}
// 51, 80, 41, 28, 55...
}
}
前面我们使用的Math.random()实际上内部调用了Random类,所以它也是伪随机数,只是我们无法指定种子。
有伪随机数,就有真随机数。实际上真正的真随机数只能通过量子力学原理来获取,而我们想要的是一个不可预测的安全的随机数,SecureRandom 就是用来创建安全的随机数的:
1
2SecureRandom sr = new SecureRandom();
System.out.println(sr.nextInt(100));
SecureRandom 无法指定种子,它使用 RNG(random number generator)算法。JDK 的 SecureRandom 实际上有多种不同的底层实现,有的使用安全随机种子加上伪随机数算法来产生安全的随机数,有的使用真正的随机数生成器。实际使用的时候,可以优先获取高强度的安全随机数生成器,如果没有提供,再使用普通等级的安全随机数生成器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import java.util.Arrays;
import java.security.SecureRandom;
import java.security.NoSuchAlgorithmException;
public class Main {
public static void main(String[] args) {
SecureRandom sr = null;
try {
sr = SecureRandom.getInstanceStrong(); // 获取高强度安全随机数生成器
} catch (NoSuchAlgorithmException e) {
sr = new SecureRandom(); // 获取普通的安全随机数生成器
}
byte[] buffer = new byte[16];
sr.nextBytes(buffer); // 用安全随机数填充buffer
System.out.println(Arrays.toString(buffer));
}
}
SecureRandom 的安全性是通过操作系统提供的安全的随机种子来生成随机数。这个种子是通过 CPU 的热噪声、读写磁盘的字节、网络流量等各种随机事件产生的 “熵”。
在密码学中,安全的随机数非常重要。如果使用不安全的伪随机数,所有加密体系都将被攻破。因此,时刻牢记必须使用 SecureRandom 来产生安全的随机数。
需要使用安全随机数的时候,必须使用
SecureRandom,绝不能使用Random!
Java提供的常用工具类有: