174. 别让自己“墙”了自己
转载
1 | ssh-keygen -t ed25519 -C "comment" -f file_name -N '' -q |
-t 选项(默认 rsa)
生成的密钥类型(不带默认为 rsa), 类型有四种分别是 dsa | ecdsa | ed25519 | rsa
-b 选项
表示生成的密钥的大小(以字节:byte 为单位)
在生成时如果指定的 key size 太小也会有安全的问题, 建议指定 key size 为 2048 或更大.
-C 选项
生成密钥的描述信息. (会追加到公钥.pub 内容的末尾)
-f 选项
文件名称, 或者文件路径.
-N 选项
指定新密码, ‘’ 表示密码为空.
-q 选项
静默模式, 直接生成密钥对, 不现实过程中产生的信息.
在 terminal 输入 ssh-keygen
进入 ~/.ssh
id_rsa 是 私钥
id_rsa.pub 是 公钥
将公钥复制到 Github下
SettingSSH and GPG keysNew SSH keyKey 中复制你的公钥Add SSH key将git下载到本地 git clone <你的仓库地址>
cd 进入 对应的文件夹
git pull 更新你的仓库
git status 以查看在你上次提交之后是否有修改
该命令加了 -s 参数, 以获得简短的结果输出. 如果没加该参数会详细输出内容.
git add 将该文件添加到缓存
git add * 将所有更改的文件, 添加进暂存git add <文件名> 将对应的文件添加进暂存git commit -m "备注" 使用 git add 命令将想要快照的内容写入缓存区, 而执行 git commit 将缓存区内容添加到仓库中.
git push 将本地库中的最新信息发送给远程库.
Notes
若已经有文件:
- 创建完git连接之后, 先
git pull一下.
commit和push的区别
git作为支持分布式版本管理的工具, 它管理的库(repository)分为本地库、远程库.
git commit操作的是本地库, git push操作的是远程库.
git commit是将本地修改过的文件提交到本地库中.
git push是将本地库中的最新信息发送给远程库.
那有人就会问, 为什么要分本地commit和服务器的push呢?
因为如果本地不commit的话, 修改的纪录可能会丢失. 而有些修改当前是不需要同步至服务器的, 所以什么时候同步过去由用户自己选择. 什么时候需要同步再push到服务器
1 | git config --global diff.tool nvimdiff |
gitdiff 在打开每一个文件的 diff 时都会进行输入确认, 设置
difftool.prompt可以禁用这一行为.
给 difftool 起个别名 vd
此后使用 git difftool 时 Git 便会调用 vimdiff 逐一打开每个文件的 Diff. 查看完成一个文件的 diff 后使用 :qa 关闭该文件 diff.
这时 Git 会自动打开下一个文件的 diff. 如果中止本次 Diff 呢?首先需要让 Git 信任 difftool 的返回码:
1 | git config --global difftool.trustExitCode true |
然后让 vimdiff 返回 1::cq (:help cquit) 退出 Vim.
git init 命令把这个目录变成Git可以管理的仓库
也不一定必须在空目录下创建Git仓库, 选择一个已经有东西的目录也是可以的.
运行git status命令查看仓库当前状态
git status命令可以让我们时刻掌握仓库当前的状态
命令git add告诉Git, 把文件添加到仓库
命令git commit告诉Git, 把文件提交到仓库
-m后面输入的是本次提交的说明, 可以输入任意内容, 当然最好是有意义的, 这样你就能从历史记录里方便地找到改动记录.
git diff顾名思义就是查看difference, 显示的格式正是Unix通用的diff格式, 看具体修改了什么内容
你不断对文件进行修改, 然后不断提交修改到版本库里, 就好比玩RPG游戏时, 每通过一关就会自动把游戏状态存盘, 如果某一关没过去, 你还可以选择读取前一关的状态. 有些时候, 在打Boss之前, 你会手动存盘, 以便万一打Boss失败了, 可以从最近的地方重新开始. Git也是一样, 每当你觉得文件修改到一定程度的时候, 就可以“保存一个快照”, 这个快照在Git中被称为commit. 一旦你把文件改乱了, 或者误删了文件, 还可以从最近的一个commit恢复, 然后继续工作, 而不是把几个月的工作成果全部丢失.
在实际工作中, 我们脑子里怎么可能记得一个几千行的文件每次都改了什么内容, 不然要版本控制系统干什么. 版本控制系统肯定有某个命令可以告诉我们历史记录, 在Git中, 我们用git log命令查看
1 | $ git log |
git log命令显示从最近到最远的提交日志, 我们可以看到3次提交, 最近的一次是append GPL, 上一次是add distributed, 最早的一次是wrote a readme file.
如果嫌输出信息太多, 看得眼花缭乱的, 可以试试加上--pretty=oneline参数:
1 | $ git log --pretty=oneline |
需要友情提示的是, 你看到的一大串类似1094adb...的是commit id(版本号), 和SVN不一样, Git的commit id不是1, 2, 3……递增的数字, 而是一个SHA1计算出来的一个非常大的数字, 用十六进制表示, 而且你看到的commit id和我的肯定不一样, 以你自己的为准. 为什么commit id需要用这么一大串数字表示呢?因为Git是分布式的版本控制系统, 后面我们还要研究多人在同一个版本库里工作, 如果大家都用1, 2, 3……作为版本号, 那肯定就冲突了.
每提交一个新版本, 实际上Git就会把它们自动串成一条时间线. 如果使用可视化工具查看Git历史, 就可以更清楚地看到提交历史的时间线
准备把readme.txt回退到上一个版本, 也就是add distributed的那个版本
首先, Git必须知道当前版本是哪个版本, 在Git中, 用HEAD表示当前版本, 也就是最新的提交1094adb...(注意我的提交ID和你的肯定不一样), 上一个版本就是HEAD^, 上上一个版本就是HEAD^^, 当然往上100个版本写100个^比较容易数不过来, 所以写成HEAD~100.
现在, 我们要把当前版本append GPL回退到上一个版本add distributed, 就可以使用git reset命令:
1 | $ git reset --hard HEAD^ |
--hard参数有啥意义?这个后面再讲, 现在你先放心使用.
还可以继续回退到上一个版本wrote a readme file, 不过且慢, 让我们用git log再看看现在版本库的状态:
1 | $ git log |
最新的那个版本append GPL已经看不到了!好比你从21世纪坐时光穿梭机来到了19世纪, 想再回去已经回不去了, 肿么办?
办法其实还是有的, 只要上面的命令行窗口还没有被关掉, 你就可以顺着往上找啊找啊, 找到那个append GPL的commit id是1094adb..., 于是就可以指定回到未来的某个版本:
1 | $ git reset --hard 1094a |
版本号没必要写全, 前几位就可以了, Git会自动去找. 当然也不能只写前一两位, 因为Git可能会找到多个版本号, 就无法确定是哪一个了.
再小心翼翼地看看readme.txt的内容:
1 | $ cat readme.txt |
果然, 我胡汉三又回来了.
Git的版本回退速度非常快, 因为Git在内部有个指向当前版本的HEAD指针, 当你回退版本的时候, Git仅仅是把HEAD从指向append GPL:
1 | ┌────┐ |
改为指向add distributed:
1 | ┌────┐ |
然后顺便把工作区的文件更新了. 所以你让HEAD指向哪个版本号, 你就把当前版本定位在哪.
现在, 你回退到了某个版本, 关掉了电脑, 第二天早上就后悔了, 想恢复到新版本怎么办?找不到新版本的commit id怎么办?
在Git中, 总是有后悔药可以吃的. 当你用$ git reset --hard HEAD^回退到add distributed版本时, 再想恢复到append GPL, 就必须找到append GPL的commit id. Git提供了一个命令git reflog用来记录你的每一次命令:
1 | $ git reflog |
终于舒了口气, 从输出可知, append GPL的commit id是1094adb, 现在, 你又可以乘坐时光机回到未来了.
HEAD指向的版本就是当前版本, 因此, Git允许我们在版本的历史之间穿梭, 使用命令git reset --hard commit_id.git log可以查看提交历史, 以便确定要回退到哪个版本.git reflog查看命令历史, 以便确定要回到未来的哪个版本.就是你在电脑里能看到的目录, 比如我的learngit文件夹就是一个工作区:
工作区有一个隐藏目录.git, 这个不算工作区, 而是Git的版本库.
Git的版本库里存了很多东西, 其中最重要的就是称为stage(或者叫index)的暂存区, 还有Git为我们自动创建的第一个分支master, 以及指向master的一个指针叫HEAD.
分支和HEAD的概念我们以后再讲.
前面讲了我们把文件往Git版本库里添加的时候, 是分两步执行的:
第一步是用git add把文件添加进去, 实际上就是把文件修改添加到暂存区;
第二步是用git commit提交更改, 实际上就是把暂存区的所有内容提交到当前分支.
因为我们创建Git版本库时, Git自动为我们创建了唯一一个master分支, 所以, 现在, git commit就是往master分支上提交更改.
你可以简单理解为, 需要提交的文件修改通通放到暂存区, 然后, 一次性提交暂存区的所有修改.
现在, 使用两次命令git add, 把readme.txt和LICENSE都添加后, 用git status再查看一下:
1 | $ git status |
所以, git add命令实际上就是把要提交的所有修改放到暂存区(Stage), 然后, 执行git commit就可以一次性把暂存区的所有修改提交到分支.
一旦提交后, 如果你又没有对工作区做任何修改, 那么工作区就是“干净”的:
1 | $ git status |
现在版本库变成了这样, 暂存区就没有任何内容了:
什么是修改?比如你新增了一行, 这就是一个修改, 删除了一行, 也是一个修改, 更改了某些字符, 也是一个修改, 删了一些又加了一些, 也是一个修改, 甚至创建一个新文件, 也算一个修改.
现有操作过程:
第一次修改 -> git add -> 第二次修改 -> git commit
Git管理的是修改, 当你用git add命令后, 在工作区的第一次修改被放入暂存区, 准备提交, 但是, 在工作区的第二次修改并没有放入暂存区, 所以, git commit只负责把暂存区的修改提交了, 也就是第一次的修改被提交了, 第二次的修改不会被提交.
git diff HEAD -- readme.txt命令可以查看工作区和版本库里面最新版本的区别
你可以继续git add再git commit, 也可以别着急提交第一次修改, 先git add第二次修改, 再git commit, 就相当于把两次修改合并后一块提交了:
第一次修改 -> git add -> 第二次修改 -> git add -> git commit
在准备提交前, 发现了错误. 既然错误发现得很及时, 就可以很容易地纠正它. 你可以删掉最后一行, 手动把文件恢复到上一个版本的状态. 如果用git status查看一下:
1 | $ git status |
你可以发现, Git会告诉你, git checkout -- file可以丢弃工作区的修改:
1 | git checkout -- readme.txt |
命令git checkout -- readme.txt意思就是, 把readme.txt文件在工作区的修改全部撤销, 这里有两种情况:
一种是readme.txt自修改后还没有被放到暂存区, 现在, 撤销修改就回到和版本库一模一样的状态;
一种是readme.txt已经添加到暂存区后, 又作了修改, 现在, 撤销修改就回到添加到暂存区后的状态.
总之, 就是让这个文件回到最近一次git commit或git add时的状态.
git checkout -- file命令中的--很重要, 没有--, 就变成了“切换到另一个分支”的命令, 我们在后面的分支管理中会再次遇到git checkout命令.
将文件git add到暂存区了
庆幸的是, 在commit之前, 你发现了这个问题. 用git status查看一下, 修改只是添加到了暂存区, 还没有提交:
1 | $ git status |
Git同样告诉我们, 用命令git reset HEAD <file>可以把暂存区的修改撤销掉(unstage), 重新放回工作区:
1 | $ git reset HEAD readme.txt |
git reset命令既可以回退版本, 也可以把暂存区的修改回退到工作区. 当我们用HEAD时, 表示最新的版本.
再用git status查看一下, 现在暂存区是干净的, 工作区有修改:
1 | $ git status |
假设你不但改错了东西, 还从暂存区提交到了版本库, 怎么办呢?还记得版本回退一节吗?可以回退到上一个版本. 不过, 这是有条件的, 就是你还没有把自己的本地版本库推送到远程. 还记得Git是分布式版本控制系统吗?我们后面会讲到远程版本库, 一旦你把stupid boss提交推送到远程版本库, 你就真的惨了……
git checkout -- file.git reset HEAD <file>, 就回到了场景1, 第二步按场景1操作.确实要从版本库中删除该文件, 那就用命令git rm删掉, 并且git commit:
1 | $ git rm test.txt |
另一种情况是删错了, 因为版本库里还有呢, 所以可以很轻松地把误删的文件恢复到最新版本
1 | git checkout -- test.txt |
git checkout其实是用版本库里的版本替换工作区的版本, 无论工作区是修改还是删除, 都可以“一键还原”.
create a new repo
1 | git remote add origin git@github.com:<github账户名>/<仓库名>.git |
添加后, 远程库的名字就是origin, 这是Git默认的叫法, 也可以改成别的, 但是origin这个名字一看就知道是远程库.
关联一个远程库时必须给远程库指定一个名字, origin是默认习惯命名.
就可以把本地库的所有内容推送到远程库上
1 | $ git push -u origin master |
把本地库的内容推送到远程, 用git push命令, 实际上是把当前分支master推送到远程.
由于远程库是空的, 我们第一次推送master分支时, 加上了-u参数, Git不但会把本地的master分支内容推送的远程新的master分支, 还会把本地的master分支和远程的master分支关联起来, 在以后的推送或者拉取时就可以简化命令.
推送成功后, 可以立刻在GitHub页面中看到远程库的内容已经和本地一模一样
从现在起, 只要本地作了提交, 就可以通过命令:
1 | git push origin master |
把本地master分支的最新修改推送至GitHub, 现在, 你就拥有了真正的分布式版本库!
如果添加的时候地址写错了, 或者就是想删除远程库, 可以用git remote rm <name>命令. 使用前, 建议先用git remote -v查看远程库信息:
1 | $ git remote -v |
然后, 根据名字删除, 比如删除origin:
1 | git remote rm origin |
此处的“删除”其实是解除了本地和远程的绑定关系, 并不是物理上删除了远程库. 远程库本身并没有任何改动. 要真正删除远程库, 需要登录到GitHub, 在后台页面找到删除按钮再删除.
分支就是科幻电影里面的平行宇宙, 当你正在电脑前努力学习Git的时候, 另一个你正在另一个平行宇宙里努力学习SVN.
如果两个平行宇宙互不干扰, 那对现在的你也没啥影响. 不过, 在某个时间点, 两个平行宇宙合并了, 结果, 你既学会了Git又学会了SVN!
在版本回退里, 你已经知道, 每次提交, Git都把它们串成一条时间线, 这条时间线就是一个分支. 截止到目前, 只有一条时间线, 在Git里, 这个分支叫主分支, 即master分支. HEAD严格来说不是指向提交, 而是指向master, master才是指向提交的, 所以, HEAD指向的就是当前分支.
一开始的时候, master分支是一条线, Git用master指向最新的提交, 再用HEAD指向master, 就能确定当前分支, 以及当前分支的提交点:
1 | HEAD |
每次提交, master分支都会向前移动一步, 这样, 随着你不断提交, master分支的线也越来越长.
当我们创建新的分支, 例如dev时, Git新建了一个指针叫dev, 指向master相同的提交, 再把HEAD指向dev, 就表示当前分支在dev上:
1 | master |
你看, Git创建一个分支很快, 因为除了增加一个dev指针, 改改HEAD的指向, 工作区的文件都没有任何变化!
不过, 从现在开始, 对工作区的修改和提交就是针对dev分支了, 比如新提交一次后, dev指针往前移动一步, 而master指针不变:
1 | master |
假如我们在dev上的工作完成了, 就可以把dev合并到master上. Git怎么合并呢?最简单的方法, 就是直接把master指向dev的当前提交, 就完成了合并:
1 | HEAD |
所以Git合并分支也很快!就改改指针, 工作区内容也不变!
合并完分支后, 甚至可以删除dev分支. 删除dev分支就是把dev指针给删掉, 删掉后, 我们就剩下了一条master分支:
1 | HEAD |
创建dev分支, 然后切换到dev分支:
1 | $ git checkout -b dev |
git checkout命令加上-b参数表示创建并切换, 相当于以下两条命令:
1 | $ git branch dev |
然后, 用git branch命令查看当前分支:
1 | $ git branch |
git branch命令会列出所有分支, 当前分支前面会标一个*号.
然后, 我们就可以在dev分支上正常提交, 比如对readme.txt做个修改, 加上一行:
1 | Creating a new branch is quick. |
然后提交:
1 | $ git add readme.txt |
现在, dev分支的工作完成, 我们就可以切换回master分支:
1 | $ git checkout master |
切换回master分支后, 再查看一个readme.txt文件, 刚才添加的内容不见了!因为那个提交是在dev分支上, 而master分支此刻的提交点并没有变:
现在, 我们把dev分支的工作成果合并到master分支上:
1 | $ git merge dev |
git merge命令用于合并指定分支到当前分支. 合并后, 再查看readme.txt的内容, 就可以看到, 和dev分支的最新提交是完全一样的.
注意到上面的Fast-forward信息, Git告诉我们, 这次合并是“快进模式”, 也就是直接把master指向dev的当前提交, 所以合并速度非常快.
当然, 也不是每次合并都能Fast-forward, 我们后面会讲其他方式的合并.
合并完成后, 就可以放心地删除dev分支了:
1 | $ git branch -d dev |
删除后, 查看branch, 就只剩下master分支了:
1 | $ git branch |
因为创建、合并和删除分支非常快, 所以Git鼓励你使用分支完成某个任务, 合并后再删掉分支, 这和直接在master分支上工作效果是一样的, 但过程更安全.
我们注意到切换分支使用git checkout <branch>, 而前面讲过的撤销修改则是git checkout -- <file>, 同一个命令, 有两种作用, 确实有点令人迷惑.
实际上, 切换分支这个动作, 用switch更科学. 因此, 最新版本的Git提供了新的git switch命令来切换分支:
创建并切换到新的dev分支, 可以使用:
1 | git switch -c dev |
直接切换到已有的master分支, 可以使用:
1 | git switch master |
使用新的git switch命令, 比git checkout要更容易理解.
git branchgit branch <name>git checkout <name>或者git switch <name>git checkout -b <name>或者git switch -c <name>git merge <name>git branch -d <name>准备新的feature1分支, 继续我们的新分支开发:
1 | $ git switch -c feature1 |
修改readme.txt最后一行, 改为:
1 | Creating a new branch is quick AND simple. |
在feature1分支上提交:
1 | $ git add readme.txt |
切换到master分支:
1 | $ git switch master |
Git还会自动提示我们当前master分支比远程的master分支要超前1个提交.
在master分支上把readme.txt文件的最后一行改为:
1 | Creating a new branch is quick & simple. |
提交:
1 | $ git add readme.txt |
现在, master分支和feature1分支各自都分别有新的提交, 变成了这样:
1 | HEAD |
这种情况下, Git无法执行“快速合并”, 只能试图把各自的修改合并起来, 但这种合并就可能会有冲突, 我们试试看:
1 | $ git merge feature1 |
果然冲突了!Git告诉我们, readme.txt文件存在冲突, 必须手动解决冲突后再提交. git status也可以告诉我们冲突的文件:
1 | $ git status |
我们可以直接查看readme.txt的内容:
1 | Git is a distributed version control system. |
Git用<<<<<<<, =======, >>>>>>>标记出不同分支的内容, 我们修改如下后保存:
1 | Creating a new branch is quick and simple. |
再提交:
1 | $ git add readme.txt |
现在, master分支和feature1分支变成了下图所示:
1 | HEAD |
用带参数的git log也可以看到分支的合并情况:
1 | $ git log --graph --pretty=oneline --abbrev-commit |
最后, 删除feature1分支:
1 | $ git branch -d feature1 |
当Git无法自动合并分支时, 就必须首先解决冲突. 解决冲突后, 再提交, 合并完成.
解决冲突就是把Git合并失败的文件手动编辑为我们希望的内容, 再提交.
用 git log --graph 命令可以看到分支合并图.
通常, 合并分支时, 如果可能, Git会用Fast forward模式, 但这种模式下, 删除分支后, 会丢掉分支信息.
如果要强制禁用Fast forward模式, Git就会在merge时生成一个新的commit, 这样, 从分支历史上就可以看出分支信息.
下面我们实战一下--no-ff方式的git merge:
首先, 仍然创建并切换dev分支:
1 | $ git switch -c dev |
修改readme.txt文件, 并提交一个新的commit:
1 | $ git add readme.txt |
现在, 我们切换回master:
1 | $ git switch master |
准备合并dev分支, 请注意--no-ff参数, 表示禁用Fast forward:
1 | $ git merge --no-ff -m "merge with no-ff" dev |
因为本次合并要创建一个新的commit, 所以加上-m参数, 把commit描述写进去.
合并后, 我们用git log看看分支历史:
1 | $ git log --graph --pretty=oneline --abbrev-commit |
可以看到, 不使用Fast forward模式, merge后就像这样:
在实际开发中, 我们应该按照几个基本原则进行分支管理:
首先, master分支应该是非常稳定的, 也就是仅用来发布新版本, 平时不能在上面干活;
那在哪干活呢?干活都在dev分支上, 也就是说, dev分支是不稳定的, 到某个时候, 比如1.0版本发布时, 再把dev分支合并到master上, 在master分支发布1.0版本;
你和你的小伙伴们每个人都在dev分支上干活, 每个人都有自己的分支, 时不时地往dev分支上合并就可以了.
所以, 团队合作的分支看起来就像这样:
Git分支十分强大, 在团队开发中应该充分应用.
合并分支时, 加上--no-ff参数就可以用普通模式合并, 合并后的历史有分支, 能看出来曾经做过合并, 而fast forward合并就看不出来曾经做过合并.
1 | wget -qO- -t1 -T2 "https://api.github.com/repos/ryanoasis/nerd-fonts/releases/latest" | grep "tag_name" | head -n 1 | awk -F ":" '{print $2}' | sed 's/\"//g;s/,//g;s/ //g' |
可以搭配 xargs 进行自定义命令
主字段
https://api.github.com/repos/ryanoasis/nerd-fonts/releases/latest 这里用的是 GitHub 的官方 API, 格式为 https://api.github.com/repos/{项目名}/releases/latest
打开上述链接后, 可见包含下述字段的内容:
1 | "html_url": "https://github.com/ryanoasis/nerd-fonts/releases/tag/v3.1.1", |
那么这里的tag_name就是我们所需要的东西啦
wget 参数
1 | wget -qO- -t1 -T2`, 在这里, 我们使用了 4 个参数, 分别是`q,O-,t1,T2 |
-q: q 就是 quiet 的意思了, 没有该参数将会显示从请求到输出全过程的所有内容, 这肯定不是我们想要的.-O-: -O是指把文档写入文件中, 而-O-是将内容写入标准输出, 而不保存为文件. (注:这里是大写英文字母 O (Out), 不是数字 0)-t1,-T2: 前者是设定最大尝试链接次数为 1 次, 后者是设定响应超时的秒数为 2 秒, 两者可以防止失败后反复获取, 导致后续脚本无法执行.筛选参数
grep "tag_name": grep 是 Linux 一个强大的文本搜索工具, 在本代码中输出 tag_name 所在行, 即输出"tag_name": "v3.1.1",head -n 1: head -n用于显示输出的行数, 考虑到某些项目可能存在多个不同版本的 tag_name, 这里我们只要第一个.awk -F ":" '{print $2}': awk 主要用于文本分析, 在这里指定:为分隔符, 将该行切分成多列, 并输出第二列. 于是我们得到了(空格)"v3.1.1",sed 's/\"//g;s/,//g;s/ //g': 在这里 sed 用于数据查找替换, 如sed 's/要被取代的字串/新的字串/g' , 因此本段命令可分为 3 个, 以分号分隔. s/\"//g即将引号删除(反斜杠是为了防止引号被转义), 以此类推, 最终留下我们需要的内容:v3.1.1.有些时候, 你必须把某些文件放到Git工作目录中, 但又不能提交它们, 比如保存了数据库密码的配置文件啦, 等等, 每次git status都会显示Untracked files ..., 有强迫症的童鞋心里肯定不爽.
好在Git考虑到了大家的感受, 这个问题解决起来也很简单, 在Git工作区的根目录下创建一个特殊的.gitignore文件, 然后把要忽略的文件名填进去, Git就会自动忽略这些文件.
[!NOTE]
.gitignore文件本身应该提交给Git管理, 这样可以确保所有人在同一项目下都使用相同的.gitignore文件.
不需要从头写.gitignore文件, GitHub已经为我们准备了各种配置文件, 只需要组合一下就可以使用了. 所有配置文件可以直接在线浏览:GitHub/gitignore
忽略文件的原则是:
.class文件;举个例子:
假设你在Windows下进行Python开发, Windows会自动在有图片的目录下生成隐藏的缩略图文件, 如果有自定义目录, 目录下就会有Desktop.ini文件, 因此你需要忽略Windows自动生成的垃圾文件:
1 | # Windows: |
然后, 继续忽略Python编译产生的.pyc、.pyo、dist等文件或目录:
1 | # Python: |
加上你自己定义的文件, 最终得到一个完整的.gitignore文件, 内容如下:
1 | # Windows: |
最后一步就是把.gitignore也提交到Git, 就完成了!当然检验.gitignore的标准是git status命令是不是说working directory clean.
使用Windows的童鞋注意了, 如果你在资源管理器里新建一个.gitignore文件, 它会非常弱智地提示你必须输入文件名, 但是在文本编辑器里“保存”或者“另存为”就可以把文件保存为.gitignore了.
有些时候, 你想添加一个文件到Git, 但发现添加不了, 原因是这个文件被.gitignore忽略了:
1 | $ git add App.class |
如果你确实想添加该文件, 可以用-f强制添加到Git:
1 | git add -f App.class |
或者你发现, 可能是.gitignore写得有问题, 需要找出来到底哪个规则写错了, 可以用git check-ignore命令检查:
1 | $ git check-ignore -v App.class |
Git会告诉我们, .gitignore的第3行规则忽略了该文件, 于是我们就可以知道应该修订哪个规则.
还有些时候, 当我们编写了规则排除了部分文件时:
1 | # 排除所有.开头的隐藏文件: |
但是我们发现.*这个规则把.gitignore也排除了, 并且App.class需要被添加到版本库, 但是被*.class规则排除了.
虽然可以用git add -f强制添加进去, 但有强迫症的童鞋还是希望不要破坏.gitignore规则, 这个时候, 可以添加两条例外规则:
1 | # 排除所有.开头的隐藏文件: |
把指定文件排除在.gitignore规则外的写法就是!+文件名, 所以, 只需把例外文件添加进去即可.
可以通过GitIgnore Online Generator在线生成.gitignore文件并直接下载.
最后一个问题:.gitignore文件放哪?答案是放Git仓库根目录下, 但其实一个Git仓库也可以有多个.gitignore文件, .gitignore文件放在哪个目录下, 就对哪个目录(包括子目录)起作用.
1 | myproject <- Git仓库根目录 |
同时使用两个 GitHub 帐号, 需要为两个帐号配置不同的 SSH Key:
生成帐号 A 的 SSH Key, 并在帐号 A 的 GitHub 设置页面添加 SSH 公钥:
1 | ssh-keygen -t ed25519 -C "GitHub User A" -f ~/.ssh/github_user_a_ed25519 |
生成帐号 B 的 SSH-Key, 并在帐号 B 的 GitHub 设置页面添加 SSH 公钥:
1 | ssh-keygen -t ed25519 -C "GitHub User B" -f ~/.ssh/github_user_b_ed25519 |
创建好了上面的多个ssh key就可以开始管理他们了. 在终端中输入如下命令, 查询系统ssh key的代理:
1 | ssh-add -l |
如果系统已经设置了代理, 需要删除:
1 | ssh-add -D |
如果提示:
1 | Could not open a connection to your authentication agent. |
执行:
1 | exec ssh-agent bash |
接下来添加刚才创建的ssh key的私钥:
1 | # 第一个 |
其实就是将对应的.pub中的内容, 复制到对应平台的ssh key管理栏目中, 不同的平台, 位置不同, 可以去对应的个人中心的设置中查看, 很容易找到.
创建或者修改文件 ~/.ssh/config, 添加如下内容:
1 | Host gt_a |
用 ssh 命令分别测试两个 SSH Key:
1 | $ ssh -T gt_a |
将 git@github.com 替换为 SSH 配置文件中对应的 Host, 如原仓库 SSH 链接为:
1 | git@github.com:owner/repo.git |
使用帐号 A 推拉仓库时, 需要将连接修改为:
1 | gt_a:owner/repo.git |
我们大多数人都会使用第三方工具进行git提交, 比如source tree之类的, 这些工具在提交时, 如果不对对应的git仓库进行专门的配置, 会默认走git的全局配置, 也就是会用默认的全局配置的账户进行git提交. 一不小心, 就会用我们私人的账户, 进行了公司项目的git提交, 生成了对应的提交记录, 也有可能因为权限问题, 导致直接提交失败.
这时, 我们需要对不同的仓库, 进行对应的配置.
检查全局配置
在终端中, 分别输入如下命令, 可以检查目前电脑中的git的全局配置信息, 如果没有返回, 说明没有全局配置, 如果有, 就可以看到对应的默认的账户是那个了.
1 | git config --global user.name |
为了避免麻烦, 我们可以取消全局配置:
1 | git config --global --unset user.name |
全局配置和局部配置
此时已经取消了电脑中默认的git全局配置信息, 此时进行git提交, 会报对应的找不到账户信息的错误.
我们可以cd到对应的git仓库的根目录下, 执行局部git配置命令. 比如 ~/github/DemoProject 是一个在github平台托管的本地git仓库的根目录, 我们可以执行如下命令:
1 | cd ~/github/DemoProject |
如果返回均为空, 说明没有进行过局部配置, 可以分别配置github的账户名和邮箱:
1 | git config user.name "github账户名" |
同理, 在不同的git仓库下, 可以分别配置不同平台的git账户名和git邮箱. 这虽然看起来麻烦, 不过, 只要设置完成, 之后只要不再更改对应的git仓库的路径, 就不需要再更换配置了.
而且, 即便我们没有取消默认的全局git配置, 在进行了局部配置后, 后者的优先级会更高. 执行:
1 | git config --list |
可以查看查看当前仓库的具体配置信息, 在当前仓库目录下查看的配置是全局配置+当前项目的局部配置, 使用的时候会优先使用当前仓库的局部配置, 如果没有, 才会去读取全局配置.
当一个 git 项目包含子模块(submodule) 时, 直接克隆下来的子模块目录里面是空的.
有两种方法解决:
如果项目已经克隆到了本地, 执行下面的步骤:
初始化本地子模块配置文件
1 | git submodule init |
更新项目, 抓取子模块内容.
1 | git submodule update |
另外一种更简单的方法, 就是在执行 git clone 时加上 --recursive 参数. 它会自动初始化并更新每一个子模块. 例如:
1 | Copygit clone --recursive https://github.com/example/example.git |
关于 git 子模块更多内容, 参见官方文档.
查看子模块: git submodule
更新子模块:
git submodule updategit submodule update --remote克隆包含子模块的项目
克隆父项目: git clone https://github.com/demo.git assets
初始化子模块: git submodule init
更新子模块: git submodule update
递归克隆整个项目submodule: git clone https://github.com/user/demo.git ./demo --recursive
> `--recursive` 表示递归地克隆 git_parent 依赖的所有子版本库.
递归更新整个项目submodule: git submodule foreach git pull
删除子模块: git rm --cached subModulesA rm -rf subModulesA
在桌面 gedit spyder.desktop
输入下面文本
1 | [Desktop Entry] |
将该文件移动到 /usr/share/applications
解决不能使用中文输入法的问题
cd /usr/lib/x86_64-linux-gnu/qt5/plugins/platforminputcontexts 找到文件所在的文件夹ls 查看当前文件夹中的文件,其实这条可以省略sudo cp libfcitxplatforminputcontextplugin.so ~/anaconda3/plugins/platforminputcontexts 将其复制到anaconda插件相应的文件下Ubuntu Server安装教程
1 | vector():创建一个空vector |
1 | iterator erase(iterator it):删除向量中迭代器指向元素 |
1 | map<int, string> m |
1 | m.insert(pair<int,string>(102,"aclive")); |
1 | for (map<int, string>::iterator iter = m.begin(); iter != m.end(); iter++) { |
m.size()1 | queue<int> q; |
1 | q.push(1); |
1 | q.pop(); |
1 | q.front(); |
1 | q.back(); |
1 | q.empty(); |
1 | q.size(); |
1 | stack<int> s; |
1 | s.push(1); |
1 | s.pop(); |
1 | s.top(); |
1 | s.empty(); |
1 | s.size(); |
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
例:
1 | >>> x = 7 |
将lambda函数赋值给一个变量,通过这个变量间接调用该lambda函数。
例如,执行语句add=lambda x, y: x+y,定义了加法函数lambda x, y: x+y,并将其赋值给变量add,这样变量add便成为具有加法功能的函数。例如,执行add(1,2),输出为3。
将lambda函数赋值给其他函数,从而将其他函数用该lambda函数替换。
例如,为了把标准库time中的函数sleep的功能屏蔽(Mock),我们可以在程序初始化时调用:time.sleep=lambda x:None。这样,在后续代码中调用time库的sleep函数将不会执行原有的功能。例如,执行time.sleep(3)时,程序不会休眠3秒钟,而是什么都不做。
将lambda函数作为其他函数的返回值,返回给调用者。
函数的返回值也可以是函数。例如return lambda x, y: x+y返回一个加法函数。这时,lambda函数实际上是定义在某个函数内部的函数,称之为嵌套函数,或者内部函数。对应的,将包含嵌套函数的函数称之为外部函数。内部函数能够访问外部函数的局部变量,这个特性是闭包(Closure)编程的基础,在这里我们不展开。
将lambda函数作为参数传递给其他函数。
部分Python内置函数接收函数作为参数。典型的此类内置函数有这些。
filter函数。此时lambda函数用于指定过滤列表元素的条件。例如filter(lambda x: x % 3 == 0, [1, 2, 3])指定将列表[1,2,3]中能够被3整除的元素过滤出来,其结果是[3]。
sorted函数。此时lambda函数用于指定对列表中所有元素进行排序的准则。例如sorted([1, 2, 3, 4, 5, 6, 7, 8, 9], key=lambda x: abs(5-x))将列表[1, 2, 3, 4, 5, 6, 7, 8, 9]按照元素与5距离从小到大进行排序,其结果是[5, 4, 6, 3, 7, 2, 8, 1, 9]。
map函数。此时lambda函数用于指定对列表中每一个元素的共同操作。例如map(lambda x: x+1, [1, 2,3])将列表[1, 2, 3]中的元素分别加1,其结果[2, 3, 4]。
reduce函数。此时lambda函数用于指定列表中两两相邻元素的结合条件。例如reduce(lambda a, b: ‘{}, {}’.format(a, b), [1, 2, 3, 4, 5, 6, 7, 8, 9])将列表 [1, 2, 3, 4, 5, 6, 7, 8, 9]中的元素从左往右两两以逗号分隔的字符的形式依次结合起来,其结果是’1, 2, 3, 4, 5, 6, 7, 8, 9’。
购买一个服务器,如在:阿里云、腾讯云上买等(阿里云有学生版);
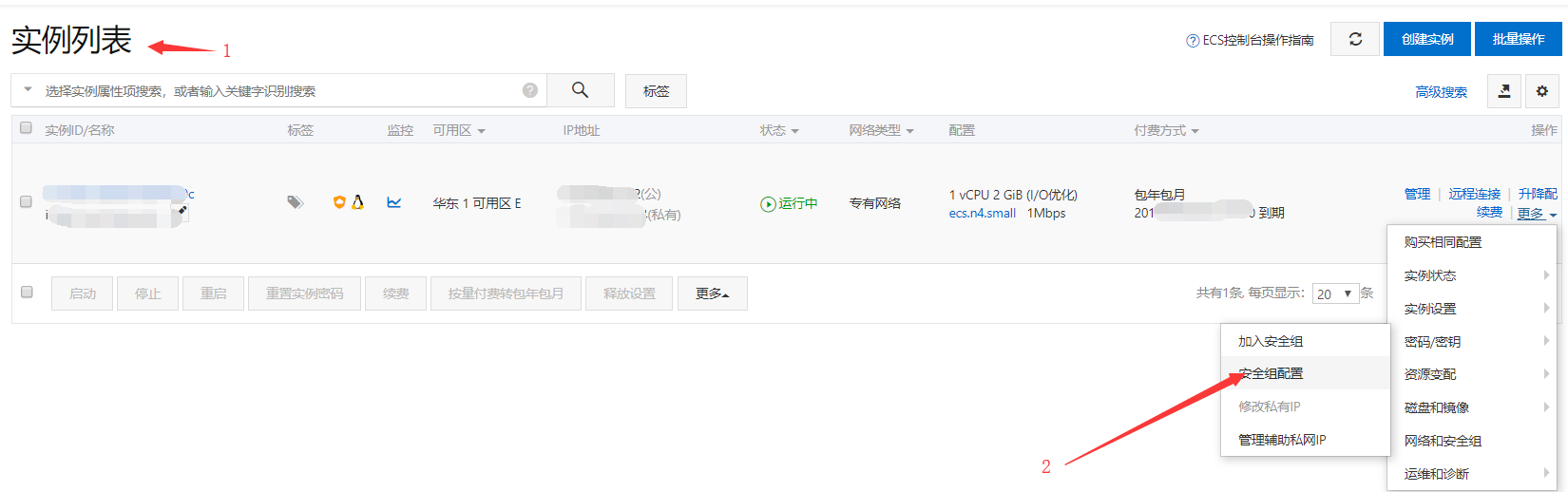
将服务器添加安全组
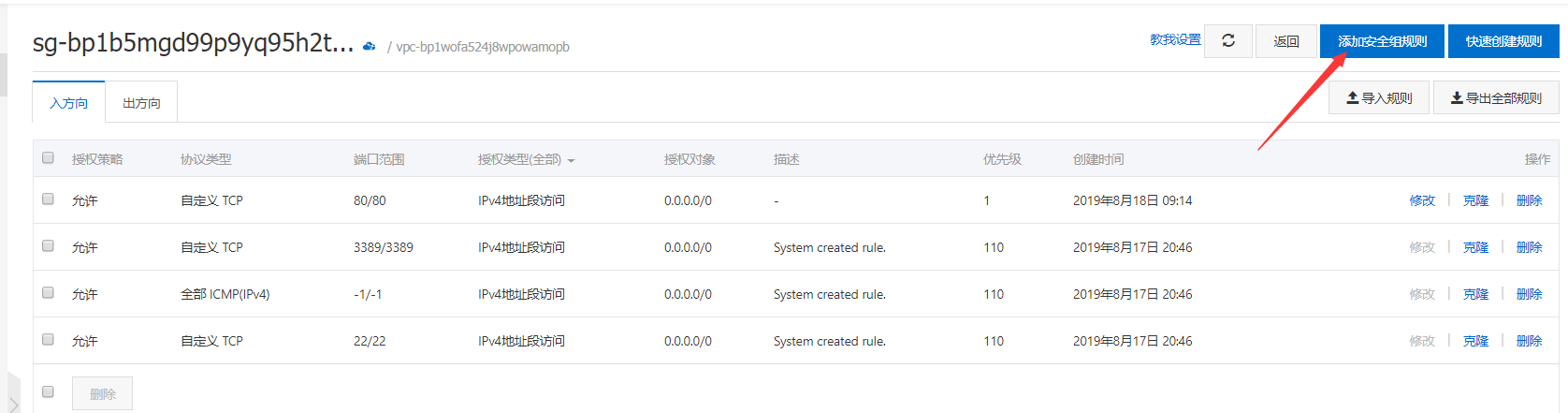
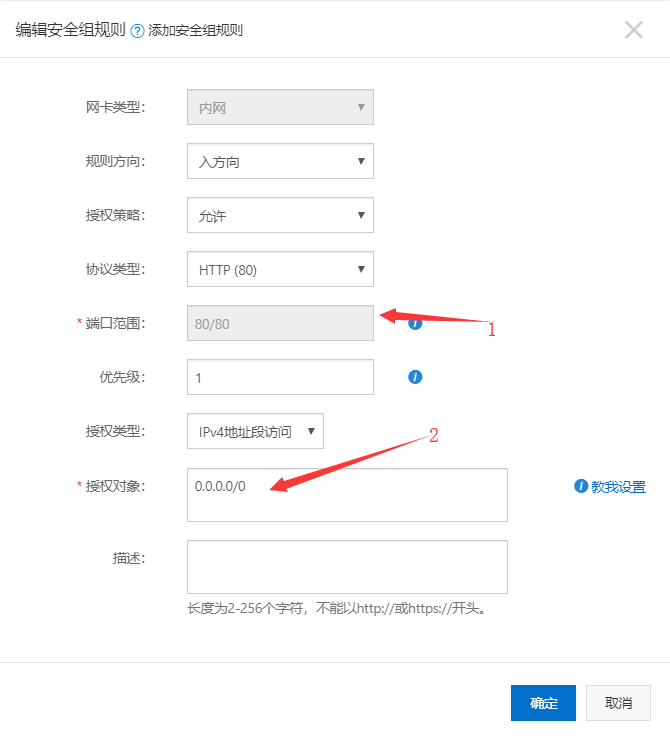
更多 - 网络和安全组 - 安全组配置 - ``,如图所示:配置规则:添加安全组规则:xshell 连接cmd 连接ssh demo@123.123.123.123demo 为用户名, 123.123.123.123为公网地址更新系统可安装的包文件,并对课升级的包,进行升级:
1 | apt update |
创建用户:adduser lqr
为用户赋予 root 权限: usermod -aG sudo lqr
切换用户: su lqr
python3 安装 pip、dev:sudo apt install python3-dev python3-pip
查看 pip3 的版本: pip3 --version
为 pip、pip3 设置镜像:
1 | pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple |
全局安装 pipenv: sudo -H pip3 install pipenv
pip3 install pipenv,也要用上面的命令装一次重新更新一遍:
1 | sudo apt update |
设置防火墙,并更新规则:
1 | sudo ufw allow 22 |
查看防火墙状态:sudo ufw status
将仓库的目录下载到本地,实例以 MMCs为例,即:lqr 目录下有 MMCs 文件夹
进入文件夹,并创建虚拟环境
1 | cd MMCs |
创建 .env: nano .env (可以直接复制)
1 | FLASK_ENV=production |
设置pipenv的镜像:
cat Pipfile1 | [[source]] |
url = "https://pypi.org/simple" 替换成: url = "https://pypi.tuna.tsinghua.edu.cn/simple/" (这里的网址,可以替换成其他镜像)进入shell,并安装 --dev、uwsgi(在 MMCs 文件夹下进行):
1 | pipenv shell |
接着执行以下命令
1 | flask init // 如果已经初始化过,这里改成 flask init --drop |
如果出现类似下面的内容,说明配置的应该是正确的
1 | * Environment: development |
然后,按 CTRL+C 结束,进行下一步
使用 Gunicorn 运行程序
pipenv install gunicornsudo ufw allow 8000sudo ufw enablegunicorn --workers=4 wsgi:appCTRL+C 结束,进行下一步键入:exit,以退出 MMCs
使用 nginx
sudo apt install nginx公网ip (例如本案例中:123.123.123.123),可以看到 welcome nginx 的界面sudo rm /etc/nginx/sites-enabled/default1 | sudo nano /etc/nginx/sites-enabled/MMCs |
1 | server { |
sudo nginx -t,如果有下面的内容说明正确:1 | nginx: the configuration file /etc/nginx/nginx.conf syntax is ok |
sudo service nginx restartgunicorn -w 4 wsgi:app使用 Supervisor 管理进程
sudo apt install supervisor1 | sudo nano /etc/supervisor/conf.d/MMCs.conf |
1 | [program:MMCs] |
1 | environment=LC_ALL='en_US.UTF-8',LANG='en_US.UTF-8' |
1 | [inet_http_server] |
supervisor 服务: sudo service supervisor restartsudo supervisorctlunzip:sudo apt install unziptemp 文件夹中1 | mkdir temp |
1 | Traceback (most recent call last): |
/usr/bin/pip3:1 | sudo nano /usr/bin/pip3 |
from pip import main 修改为 from pip._internal import main ,即可pipenv install --dev 安装依赖,出现安装超时:ReadTimeoutError,那么将 .env 的文件添加 PIPENV_TIMEOUT=36001 | flask init --drop |
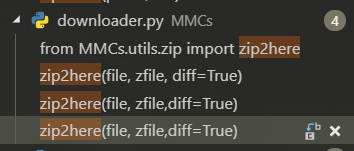
diff更改为 true,见下图:[错误日志]
1 | [2019-08-20 11:24:30,814] - MMCs - 60.2.111.59 requested http://47.98.142.112/admin/score/download/teacher |
matplotlib多轴绘制
wps使用过程中的信息储备
安装win10后安装ubuntu及其美化